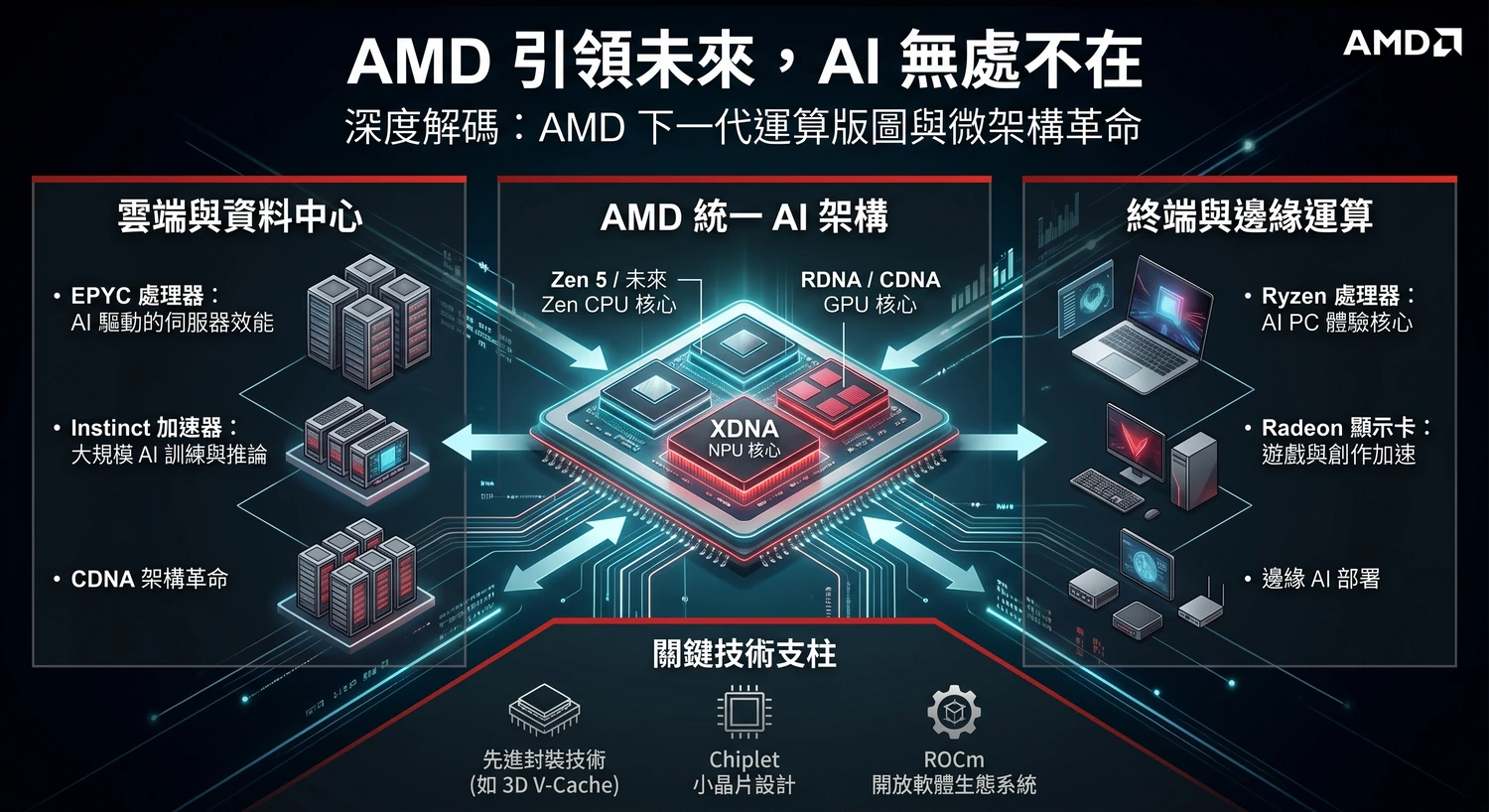
在 AI 與高效能運算需求快速爆發下,全球半導體產業正從過去單純依賴摩爾定律,轉向異質整合、先進封裝與軟體生態協同發展的新競爭階段。透過兩場 AMD 高層深度訪談可以看出,AMD 未來五至十年的核心戰略,已明確圍繞「AI 無處不在」展開,並試圖將 AI 運算能力從資料中心的大型語言模型訓練與推論,延伸到邊緣裝置、AI PC 與更多終端應用場景。
在 AI 與高效能運算需求快速爆發下,全球半導體產業正從過去單純依賴摩爾定律,轉向異質整合、先進封裝與軟體生態協同發展的新競爭階段。透過兩場 AMD 高層深度訪談可以看出,AMD 未來五至十年的核心戰略,已明確圍繞「AI 無處不在」展開,並試圖將 AI 運算能力從資料中心的大型語言模型訓練與推論,延伸到邊緣裝置、AI PC 與更多終端應用場景。
這也代表硬體設計思維正在改變。未來的運算平台不再時追求更先進製程與更多電晶體,而是更重視 CPU、GPU、NPU 之間的異質融合,並透過記憶體架構、資料傳輸效率與先進封裝技術提升整體效能。AMD 的下一代運算藍圖不只是產品規格升級,而是一次從雲端資料中心到個人裝置的完整架構轉型,未來也將深刻影響 3C、雲端與 AI 運算市場的競爭格局。
核心微架構的深度解構:AMD Zen 架構的持續突破與戰略分化
AMD 日前由高階主管出來分享平台佈局和最新發展,訪談內容中佔據最為核心且技術密度最高的篇幅,是對下一代 Zen 架構 (特別是 Zen 5 及其後續微架構演進) 的深度探討。這不僅代表了傳統 x86 架構在指令週期效能 (Instructions Per Clock, IPC) 上的極限探索,更反映出針對現代雲端與邊緣應用場景進行微架構分化 (Micro-architectural Bifurcation) 的必然趨勢。

底層邏輯創新與指令週期效能的實質躍升
Zen 5 架構的核心設計理念,是針對資料吞吐量進行一次由內而外的全面翻新。不同於前幾代較偏向頻率提升與製程微調,Zen 5 在前端管線、執行單元與記憶體子系統上都進行大幅重構。透過雙解碼器管線、更強的分支預測器、更大的 BTB 與零氣泡條件分支技術,Zen 5 能提升指令分派效率,減少管線停頓,讓後端運算資源維持更高利用率。
在後端執行方面,Zen 5 最大升級之一是支援真正的 512 位元資料路徑,可更完整發揮 AVX-512 指令集效能,對 AI 資料處理、科學運算與金融建模等高度依賴向量運算的工作負載特別有利。同時,AMD 也透過時脈閘控、細粒度電源管理與動態電壓頻率調整,在控制功耗與熱密度的前提下提升效能功耗比。這也代表未來 CPU 效能競爭將不再只是拉高時脈,而是轉向提升單一時鐘週期內的資料吞吐能力。
邊緣運算與高密度核心架構的成熟化佈局
AMD 高層在訪談中多次強調,高密度運算架構如 Zen 4c、Zen 5c,已成為資料中心市場的重要戰略。這類核心透過縮小 L3 快取與核心面積,換取更高的核心密度,並非單純犧牲效能,而是針對雲端原生工作負載所做的精準取捨。
對微服務、網頁伺服器叢集、分散式資料庫等應用來說,真正的效能瓶頸往往不是單核極限效能,而是大量執行緒的併發能力。Zen c 架構在維持與標準 Zen 核心相同指令集相容性的前提下,讓單一 CPU 插槽可容納更多核心,進一步提升每個機架的運算密度。對超大規模雲端服務商而言,這代表在相同空間與電力限制下,可以提供更多運算實例,直接提升資料中心的營運效率與商業價值。
伺服器市場的統治力深化與資料中心經濟學重塑
在伺服器處理器市場中,AMD Turin 世代的核心優勢,來自更高核心密度、更強能效比,以及對資料中心 TCO 的直接改善。隨著企業與雲端服務商對 CAPEX 與 OPEX 控制越來越嚴格,能在相同機房空間與功耗限制下提供更多運算能力,已成為伺服器平台競爭的關鍵。Turin 透過微架構與高密度設計優勢,進一步強化 AMD 在企業級與雲端市場的競爭力。
同時現代伺服器 CPU 的角色也不再只是單純運算核心,而是整個資料中心資料流動的樞紐。透過 PCIe 5.0、未來 PCIe 6.0 與 CXL 技術整合,CPU 能更高效連接記憶體池、AI 加速卡、SmartNIC 與 DPU,逐步打破傳統伺服器受限於本機記憶體通道的架構瓶頸。這也代表未來資料中心將朝向資源解耦、軟體定義與動態資源池化發展,讓運算、記憶體與儲存能依照工作負載需求更彈性配置。
資料中心與 AI 運算的巨獸:CDNA 架構與加速器生態
在圖形處理與 AI 加速領域,AMD 正採取雙軌發展策略:RDNA 持續面向遊戲、繪圖與消費級顯示市場,CDNA 則專注於資料中心 AI 與高效能運算。從訪談內容來看,CDNA 的戰略意義已不只是 GPU 架構升級,而是 AMD 挑戰 AI 加速器市場、擴大資料中心版圖的關鍵核心。透過先進製程、Chiplet 設計與高頻寬記憶體封裝技術,AMD 試圖在 AI 訓練、推論與 HPC 場景中建立更具競爭力的加速平台。
CDNA 架構的演進:從圖形渲染到純粹的張量運算引擎
CDNA 架構的發展,本質上是 AMD 將 GPU 從傳統圖形渲染任務中抽離,轉向專為大規模矩陣運算與 AI 加速打造的運算架構。從 MI300 系列到下一代 MI400,AMD 的核心策略是透過先進封裝、Chiplet 設計與高頻寬記憶體,解決大型 AI 模型在訓練與推論中最關鍵的瓶頸:記憶體容量與頻寬不足。
以 MI300X 為例,其高達 192 GB 的 HBM3 記憶體容量,讓大型模型能在更少 GPU 數量下完成載入與推論,減少跨節點資料傳輸帶來的延遲、網路設備需求與整體功耗。搭配矽中介層、3D 堆疊與超寬資料匯流排,CDNA 能提供每秒數 TB 等級的記憶體頻寬,讓矩陣運算單元持續獲得資料供應,進一步提升有效算力。這也是 AMD 試圖打破 AI 加速器市場既有格局、吸引大型雲端服務商導入 MI 系列加速器的關鍵。
消費級繪圖技術的典範轉移:RDNA 架構與 AI 渲染的融合
相較於 CDNA 在資料中心 AI 加速市場的強勢進攻,RDNA 架構在消費級顯示卡市場則採取更務實、精準的定位策略。隨著遊戲畫質、光線追蹤、AI 升頻與功耗限制不斷提高,消費級 GPU 已不再只是單純比拚傳統光柵化效能,而是進入效能、能耗、價格與軟體體驗全面平衡的新階段。RDNA 的發展重點,正是如何在有限功耗與成本下,提供更符合主流玩家需求的遊戲與圖形體驗。
放棄無效軍備競賽 轉向邊際效應最大化
AMD 在消費級獨立顯示卡市場的策略,正從過去追逐超高階旗艦效能,轉向更務實的中高階與主流市場。原因在於先進製程成本快速攀升,超大面積 GPU 晶片不只良率壓力高,終端售價也容易超出多數玩家能接受的範圍。因此,RDNA 後續世代將更重視 Chiplet 設計、光線追蹤單元最佳化,以及 AI 輔助運算的整合,而不是單純堆高功耗與晶片規模。
未來消費級 GPU 的效能提升,也將不再只依賴傳統光柵化效能,而是更仰賴 AI 升頻與畫格生成技術。透過在 RDNA 架構中導入矩陣運算與 AI 推論加速能力,AMD 可在控制功耗與成本的前提下,提升 FSR、光線追蹤與高解析度遊戲體驗。同時,RDNA 技術也會持續下放到 APU、輕薄筆電與掌機平台,進一步擴大 AMD 在遊戲與行動運算生態中的滲透率。
AI 無處不在:XDNA 架構與 Ryzen AI 的邊緣運算革命
訪談中最具前瞻性的重點,是 AMD 將 AI 運算能力從雲端下放到 AI PC 與邊緣裝置的戰略布局。隨著雲端 AI 推論成本持續攀升,加上網路延遲、資料隱私與法規合規壓力增加,讓更多 AI 任務在本地端執行,已不只是行銷口號,而是未來軟硬體生態必須共同推動的方向。這也代表 AI PC 與邊緣運算將成為 AMD 下一階段擴大市場影響力的重要戰場。
AI PC 時代的硬體定義與空間架構設計
在 AI PC 與邊緣運算浪潮中,AMD 的 XDNA 架構 NPU 成為關鍵角色。隨著微軟等平台業者對下一代 AI PC 提出更高算力門檻,NPU 必須在低功耗下提供 40 至 50 TOPS 以上的 AI 推論能力,才能支撐即時翻譯、視訊背景處理、本地端小型語言模型等背景 AI 任務,並避免影響 CPU 與 GPU 的主要效能。
XDNA 的優勢在於採用空間架構與資料流執行模型,透過分散式 AI 引擎陣列與高速內部互連,讓資料能在運算單元之間直接流動,減少頻繁存取外部記憶體所造成的功耗浪費。這使筆電能在長時間執行背景 AI 工作時,仍維持較佳續航力,也讓本地端 AI 從概念逐步走向實際應用。
軟硬體協同作戰:從矽智財到開發者生態的巨大跨越
AMD 高層也清楚指出, AI PC 的競爭不能只看 TOPS 數字,硬體算力再強,如果開發者無法輕鬆調用,最終也難以轉化成實際應用價值。因此,AMD 的角色正在從單純的晶片供應商,轉向軟硬體整合的平台提供者。
透過 Ryzen AI 軟體平台,開發者可以使用 PyTorch、TensorFlow、ONNX 等常見工具,將雲端訓練好的 AI 模型編譯、量化並部署到本地 NPU 上執行。這代表晶片廠商正開始承擔更多軟體生態建設工作,包括編譯器、模型最佳化與開發工具鏈,藉此降低 AI 應用落地門檻。對 AMD 來說,完整的軟硬體生態不只是推動 AI PC 普及的關鍵,也是面對 ARM 陣營與其他競爭者時的重要護城河。
突破摩爾定律的物理枷鎖:先進封裝與邊緣運算的護城河
訪談中反覆強調,先進封裝已成為 AMD 突破摩爾定律物理與成本限制的關鍵路徑。隨著電晶體微縮逐漸逼近極限,單靠製程從 5 奈米推進到 3 奈米或 2 奈米,已不再能穩定帶來過去那種明顯的效能提升與成本下降。因此,未來晶片競爭的重點,將從單純追求更先進製程,轉向透過 Chiplet、3D 堆疊與邊緣運算,把不同運算單元、快取與記憶體更有效率地整合在一起。
Chiplet 小晶片設計哲學的經濟學模型與良率優勢
Chiplet 小晶片架構,是 AMD 先進封裝戰略的核心。透過將傳統大型單晶片拆解成運算核心、I/O、記憶體控制器等不同功能區塊,AMD 可以依照需求採用不同製程,例如運算核心使用先進製程,I/O 晶片則使用成熟且成本較低的製程,藉此兼顧效能、成本與製造彈性。
這種設計最大的優勢在於良率與產品彈性。晶片面積越大,製造缺陷導致報廢的機率越高;拆成多個小晶片後,良率可明顯提升,也能降低高階處理器成本。同時,AMD 可以透過不同數量的運算小晶片與標準化 I/O 晶片組合,快速衍生出筆電、桌機到伺服器等完整產品線。這種模組化設計不只提高研發效率,也讓 AMD 能更快回應市場需求變化。
3D V-Cache 技術的垂直堆疊與熱力學挑戰
3D V-Cache 已從最初主打消費級遊戲市場,逐步擴展到資料中心與專業運算領域。這項技術透過先進 3D 堆疊封裝,將大容量 SRAM 快取直接堆疊在運算核心上方,大幅提升 L3 快取容量,對 CFD、EDA、氣象模擬等高度依賴大型資料集且對記憶體延遲敏感的工作負載來說,能有效降低資料存取瓶頸並提升效能。不過,垂直堆疊也帶來更嚴峻的散熱與結構挑戰,因為運算核心產生的熱必須穿過上方快取晶片才能導出,使熱密度與封裝應力更難控制。這也代表未來先進封裝不再只是晶片連接技術,而是結合材料科學、散熱設計、結構工程與訊號完整性的複雜系統工程。
軟體定義硬體:ROCm 生態系的全面反攻與開源戰略
儘管 AMD 在微架構與先進封裝上取得明顯進展,但高層在訪談中也坦承,軟體生態仍是過去幾年面臨的最大挑戰之一。對於想打破 AI 算力市場既有壟斷格局的 AMD 來說,硬體規格再強,最終仍必須依靠完整、穩定且開發者友善的軟體棧,才能真正被雲端服務商、企業客戶與開發者大規模採用。換句話說,軟體生態的成熟度,將直接決定 AMD AI 加速器能否把硬體潛力轉化為實際市場競爭力。
打破 CUDA 壁壘:零程式碼修改與擁抱開源的突圍策略
長期以來,競爭對手透過 CUDA 等封閉且高度最佳化的軟體生態,建立了極高的開發者黏著度與轉換門檻,讓許多 AI 應用、科學運算函式庫與研究程式碼深度綁定在特定架構上。為了突破這道壁壘,AMD 近年重新定位 ROCm,從單純的底層驅動與運算平台,升級為更完整、開源且重視開發者體驗的軟體生態系。新版 ROCm 的重點,是強化對 PyTorch、JAX 等主流 AI 框架的原生支援,目標是讓開發者能在盡量少修改甚至不修改程式碼的情況下,將既有模型遷移到 AMD CDNA 加速器上執行。這不只降低企業與研究機構更換硬體平台的技術風險,也成為 AMD 挑戰既有 AI 加速器市場格局的關鍵基礎。
模型最佳化編譯器與開發者體驗的量子躍進
AMD 正高度重視 Triton 等新興開源編譯器技術,並將其視為縮短與既有 GPU 軟體生態差距的關鍵工具。Triton 讓開發者能用接近 Python 的語法撰寫高效能 GPU 自訂核心,不必深入處理底層硬體細節,就能獲得接近手寫 CUDA 的效能。對 AMD 來說,若能在編譯器後端與指令集最佳化上完整支援 Triton,就能借助開源社群力量,快速補強底層算子與函式庫生態。
同時,AMD 也透過與 Hugging Face 等開源 AI 平台合作,確保最新大型語言模型能更快在 AMD 硬體上完成最佳化與部署。這代表 AMD 的競爭策略已從單純賣硬體,轉向以開源工具、模型生態與軟體最佳化來推動硬體採用。未來資料中心客戶是否願意導入 AMD AI 加速器,關鍵不只在硬體規格,而在於整套開源軟體生態能否真正降低遷移成本。
競爭態勢與總體市場展望:多線作戰的嚴峻挑戰與歷史機遇
AMD 未來五年的競爭環境將更加複雜。在雲端資料中心、邊緣運算與終端消費市場三大戰場,AMD 都將面對資源雄厚、技術積累深厚的競爭對手。因此,未來 AMD 的關鍵不只在於硬體架構是否領先,更在於能否精準掌握市場定位、快速調整產品策略,並維持穩定且具韌性的供應鏈與軟體生態執行力。
對決算力霸主:在 AI 資料中心市場的差異化與開放戰略
在資料中心 AI 加速器市場,AMD 面對的是高度垂直整合的封閉式競爭生態。主要競爭對手透過 GPU、專屬高速互連、閉源軟體棧與伺服器整機方案,建立強大的客戶綁定能力。對此,AMD 的反制策略是走向開放與標準化,透過參與 Ultra Ethernet Consortium 等開放互連標準,降低客戶對單一供應商與專屬網路技術的依賴。
這種開放策略特別符合大型雲端服務商的需求,因為 CSP 最擔心的是被單一硬體與軟體生態鎖死。AMD 透過提供更高的組件彈性,讓客戶能自由整合 AI 加速器、標準網路設備與儲存系統,進一步降低 TCO 並提升供應鏈安全。同時,MI 系列在 HBM 容量與頻寬上的優勢,也精準切中大型模型推論對記憶體的需求,成為 AMD 切入一線雲端服務商供應鏈的重要突破口。
防禦與全面反擊:應對傳統 x86 霸主與新興 ARM 架構的雙面夾擊
在傳統 x86 CPU 市場,AMD 雖然憑藉 Zen 架構持續擴大市佔,但競爭對手也正透過製造部門重組、先進製程與 2.5D / 3D 封裝技術加速反攻。因此,AMD 接下來不只要確保 Zen 架構持續穩定演進,也必須掌握先進製程與封裝產能,特別是台積電 3 奈米、2 奈米與 CoWoS 等關鍵資源。在伺服器市場,供應鏈韌性與產能分配能力,已經成為和架構設計同等重要的競爭關鍵。
另一方面,在輕薄筆電、 AI PC 與邊緣裝置市場,ARM 陣營正憑藉低功耗、快速喚醒與高效媒體能力,對傳統 x86 架構形成壓力。AMD 的反擊策略,是透過高度邊緣運算 SoC,將 Zen 高效能核心、Zen c 高密度核心、RDNA 內顯與 XDNA NPU 整合在單一平台中,兼顧效能、圖形與 AI 推論需求。同時,AMD 也必須與作業系統廠商深度合作,優化執行緒排程、休眠狀態與電源管理,才能在能耗比與使用體驗上對抗 ARM 陣營,守住下一代行動運算與 AI PC 市場。
總結
綜合兩場 AMD 高層訪談可以看出,AMD 正從過去以 CPU、GPU 硬體規格競爭為主的晶片供應商,逐步轉型為涵蓋雲端資料中心、AI 加速器、AI PC、邊緣裝置與軟體生態的全方位智慧運算平台提供者。其核心戰略圍繞「AI 無處不在」展開,並透過 Zen、CDNA、RDNA、XDNA、Chiplet、3D V-Cache 與 ROCm 等技術,建構從底層硬體到上層開發工具的完整運算版圖。
在 CPU 領域,AMD 透過 Zen 架構分化與高密度核心設計,提升資料中心的核心密度、能效比與 TCO 優勢;在 GPU 與 AI 加速領域,CDNA 與 MI 系列則依靠大容量 HBM、先進封裝與高頻寬設計,切入大型 AI 模型訓練與推論市場;在 AI PC 與邊緣運算領域,XDNA NPU 與 Ryzen AI 平台則負責將本地 AI 推論能力帶進個人裝置,讓 AI 從雲端走向終端。
不過,AMD 的挑戰同樣明顯。先進製程與封裝產能成本持續攀升,ROCm 軟體生態仍需進一步成熟,資料中心 AI 市場也面臨封閉生態強敵、 x86 傳統競爭者反攻,以及 ARM 陣營在行動運算與 AI PC 的壓力。未來 AMD 能否持續擴大影響力,關鍵不只在硬體效能,而在於邊緣運算、能效最佳化、供應鏈韌性與開源軟體生態能否同步到位。這也將決定 AMD 在未來十年 AI 與半導體產業格局中的真正位置。