

NVIDIA 正式發佈全新 GeForce RTX 4080 顯示卡,採用全新 AD103 繪圖核心、升級新一代 Ada Lovelace GPU 微架構,CUDA Core 增加至 9,728 個、第 3 代 RT Core 及第 4 代 Tensor Core、16GB GDDR6X 容量,與上代架構相比光柵化性能提升 2 倍、Ray Tracing 性能提升 4 倍,新卡性能較 RTX 3080 Ti 快 1 倍但功耗降低 10%,官方定價 NT$ 42,990 起,以下將用 GeForce RTX 4080 Founder Edition 與 RTX 3080 Ti 進行測試。
NVIDIA GeForce RTX 4080 系列登場
在 10 月推出 GeForce RTX 4090 之後,NVIDIA 15 日再發佈 GeForce RTX 4080 系列,採用全新 Ada Lovelace 微架構,原本這個系列共有 2 個型號,分別是採用 AD103 繪圖核心的 RTX 4080 16GB 與採用 AD104 繪圖核心的 RTX 4080 12GB,雖然同樣叫 RTX 4080 但兩者規格與性能差異頗大,被許多網友指責型號混亂,最終 NVIDIA 官方取消了 RTX 4080 12GB 的推出計劃,只保留 GeForce RTX 4080 16GB 型號。
與之前的 Ampere GPU 架構相比,NVIDIA Ada Lovelace GPU 在光柵化遊戲中的速度提升達 2 倍,在光線追蹤遊戲中的速度提升達 4 倍,主要有四大關鍵創新︰

革命性的架構規模提升
Ada Lovelace GPU 架構規模大大提升,在製程創新下 NVIDIA 工程師能製造出具有 763 億個電晶體、擁有高達 18,432 個 CUDA Core 晶片,並且能運作超過 2.5GHz 時脈以上,卻可以保持與 GeForce RTX 3090 Ti 相同的 450W TGP 功耗表現。
更強大的 Ada Lovelace RT Core
為了實現更強大的光線追蹤能力,Ada Lovelace GPU 架構升級第 3 代 RT Core 新增了兩個硬體單元;Opacity Micromap Engine 可將經過 alpha 測試的幾何體的光線追蹤速度提升 2 倍,而 Displaced Micro-Mesh Engine 可即時產生 Displaced Micro-Triangles 以建立額外的幾何體,能大大增加光線追蹤的復雜卻不會對 GPU 性能及儲存造成負擔。
著色器執行重新排序
Ada Lovelace GPU 架構的 SM 支援著色器執行重新排序,可以動態組織及重新排程著色器的工作負載,令光線追蹤的著色效率大大提升,在 Cyberpunk 的 RT : Overdrive 模式中,性能相較上代 SM 提升 44%。
NVIDIA DLSS 3 技術
Ada Lovelace GPU 架構新增 DLSS 3 技術,升級第 4 代 Tensor Cores 新增全新的光流加速器能提供 AI 畫幀產生功能,可將 DLSS 3 的幀速率提升至之前的 DLSS 2.0 的 2 倍,同時保持或超過原生影像品質,並且新增 FP8 張量運算能力,與傳統的蠻力圖形渲染相比,DLSS 3 最終速度提高了 4 倍,同時提供了低系統延遲。

NVIDIA 正式發佈 GeForce RTX 4080 型號,基於 AD103 繪圖核心、擁有 9,728 個 CUDA Cores、16GB GDDR6X 容量,官方定價 US$1,199,性能是上代 RTX 3080 Ti 的 1 倍,但GP 功耗降低了 10%,如果在 4K + RT 啟動下遊戲性能更可以達至 RTX 3080 Ti 的 1.5 倍。
原計劃同時發佈 GeForce RTX 4080 12GB 型號,但受到外界激烈的反對聲音,NVIDIA 最終決定取消 GeForce RTX 4080 12GB,很大機會改為明年 1 月以 GeForce RTX 4070 Ti 名義上市,但規格不會改變,售價未定。
TSMC 4N 製程、NVIDIA AD103 繪圖核心
NVIDIA AD103 繪圖核心基於全新 Ada Lovelace 微架構,並用於 GeForce RTX 4080 產品之中,性能提升主要來自 FP32 運算單元數目及時脈倍增,更大的 L2 Cache 容量及全新著色器執行排序技,術,升級第 3 代 RT Cores、升級第 4 代 Tensor Cores,與上代比較 Ampere GPU 微架構比較,傳統光柵圖形運算提高了 2 倍,同時在光線追蹤性能上提升近 4 倍。
GeForce RTX 4080 採用 AD103-300 繪圖核心,採用 TSMC 4N NVIDIA Custom 制程,擁有 459 億個電晶體、 Die Size 379mm² 相較上代 GeForce RTX 3090 的 GA102-200 Die Size 628mm² 細小得多,完整的 AD103 晶片內建 7 個 GPC 單元、 42 個 TPC 紋理處理群集及 84 個 SM 串流處理器,具備 10752 個 CUDA Cores、84 個 RT Cores 及 336 個 Tensor Cores。

不過,GeForce RTX 4080 部份單元作出了遮蔽,雖然保持 7 個 GPC 單元,但減少至 38 個 TPC 紋理處理群集及 76 個 SM 串流處理器,具備 9,278 個 CUDA Cores、76 個 RT Cores 及 304 個 Tensor Cores。
核心時脈方面,採用 TSMC 4N 製程令這代 Ada Lovelace 的核心時脈可大幅提升,GeForce RTX 4090 預設時脈 2,205MHz、加速時脈為 2,505MHz,最高 TDP 為 320W。

記憶體方面,GeForce RTX 4080 採用更高速度的 22.4Gbps GDDR6X 記憶體顆粒,雖然記憶體容量增至 16GB,但記憶體頻寬則降至 256bit,總記憶體頻寬降至 716.8GB/s,相較 RTX 3080 的 760GB/s 還要少,不過 Ada Lovelace 其中一個重大改良是 L2 Cache 容量大幅增加,上代 RTX 3080 的 L2 Cache 只有 5120KB,今代 RTX 4080 則大幅提升至65536 KB,相較 AMD 的 Infinity Cache 作為 L3 Cache 擁有更高效率,能大幅升遊戲 Workload 資料命中率,降低讀取延遲達並減少 GDDR6X 記憶體頻寬使用。
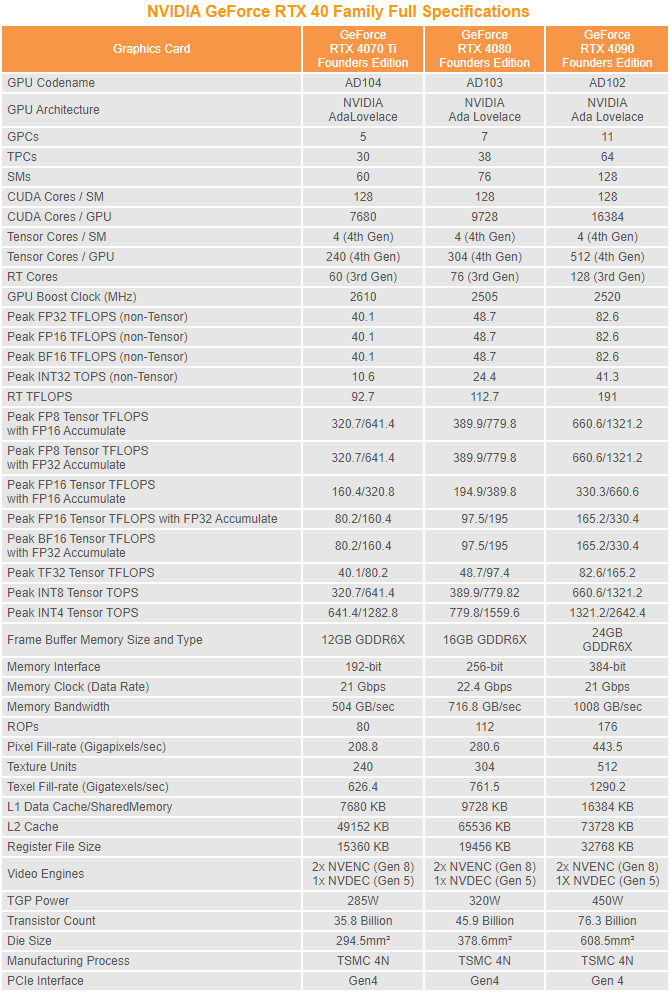
經改良的 Ada Lovelace 架構
GPC 是 NVIDIA GPU 中最頂層的硬體塊,所有關鍵圖形處理單元都位於 GPC 中。 Ada Lovelace 每個 GPC 包括 1 個專用的光柵引擎、 2 個光柵操作 (ROP) 分區,每個分區包含 8 個單獨的 ROP 單元和 6 個 TPC,每個 TPC 包括 1 個 PolyMorph 引擎和 2 個 SM。
AD102 GPU 中的每個 SM 包含 128 個 CUDA Core、1 個 Ada Lovelace 第三代 RT 核心、4 個 Ada Lovelace 第四代 Tensor 核心、4 個 Texture 紋理單元、 1 個 256 KB 檔案暫存器和 128 KB 的 L1/共享記憶體,可根據圖形或計算工作負載需求分配成不同的記憶體大小。

與 Ampere GPU 一樣,AD102 的 SM 單元分為 4 個分區,每個分區包含 1 個 64 KB 檔案暫存器、一個 L0 指令快取、一個 warp 調度程序、一個調度單元、16 個專用於處理 FP32 的 CUDA 核心操作,每個週期最多可處理 16 個 FP32 操作,16 個可以處理 FP32 或 INT32 操作的 CUDA 核心,每個週期 16 個 FP32 操作或每個時鐘 16 個 INT32 操作, 4 個加載 / 儲存單元,以及執行超越和圖形插值指令的特殊功能的 SFU 單元,除了換上第 4 代的 Tensor Core 設計,FP 單元在微架構上並沒有太大變動。

與上代 Ampere GPU 相比,Ada Lovelace GPU 的 L2 Cache 進行了徹底改造,完整的 AD103 GPU 擁有高達 65536 KB 的 L2 快取,相比 GA102 中的 6144 KB 提高了 10 倍,所有應用程序都將受益於擁有如此龐大、更高速的 L2 Cache,例如 Ray Tracing 光線追踪當中的路徑追踪之類的複雜操作將產生最大的好處,相較 AMD 的 Infinity Cache 作為 L3 Cache 擁有更高效率,能大幅升遊戲 Workload 資料命中率,降低讀取延遲並減少 GDDR6X 記憶體頻寬使用。
此外,AD103 GPU 受惠於 TSMC 4N 製程,在 NVIDIA 工程師與 TSMC 密切合作下令 AD103 包含的 CUDA 核心跟上一代 GA102 差不多,但 Die Size 卻縮減少約 39%,擁有高達 459 億個電晶體較上代多 38%,並且關鍵路徑中使用高速電晶體設計,令 AD103 GPU 時脈可運作於 2.5GHz 甚至更高,並提供了更出色的能耗比,RTX 4080 性能是 RTX 3080 Ti 的 1 倍,但功耗卻降低了 10%,如果啟用 RT + DLSS 3 技術後,性能提升甚至最高可達 3 倍。
升級第 3 代 Ray Tracing 引擎
Ray Tracing 光線追踪技術是一種密集型渲染技術,可以逼真地模擬場景及物件的光線,即時以物理方式渲染正確的反射、折射、陰影及間接照明效果。過去的 GPU 架構並無法對遊戲及圖形進行複雜的即時光線追踪處理,NVIDIA 經過過 10 年的研究及開發,終於在上代 GeForce RTX 20 的「Turing」GPU 微架構中加入硬體光線追踪加速引擎 —「RT Cores」,結合 NVIDIA RTX 軟體引擎,實現逼真的即時光線場景效果。

到了 GeForce RTX 30 系列的 Ampere GPU 升級了第 2 代的 RT Cores,BVH 遍歷與射線三角交測運算能力提升了 2 倍,第 1 代 Turning SM 在 Ray Tracing 運算時不能同時執行 Graphics 或 Compute 運算,到了 Ampere SM 強化了異步運算能力,當執行 Ray Tracing 運算時可同步進行繪圖或運算,令 Ray Tracing 的遊戲執行效率大大提升。

來到 GeForce RTX 40 的 Ada Lovelace GPU 升級至第 3 代 RT Cores,它的 Triangle Intersection Engine 相較上代快 2 倍的 Ray-Triangle 相交吞吐量,能為遊戲場境中添加更多細節,同時有快 2 倍的 Alpha Traversal 處理能力,新增 Opacity Micromap Engine 直接對幾何物件進行 alpha 測試,並顯著減少基於著色器的 alpha 運算量。
在 Ada Lovelace GPU 之前,當光線扭曲投射到不同程度透明級別的物件時,例如葉子或火焰等雜形狀通常使用紋素的 alpha 通道來表示,單個光線運算也可能需要多次著色器調用才能完成,即使光線只是簡單地表徵為命中或未命中都需要大量的運算成本。
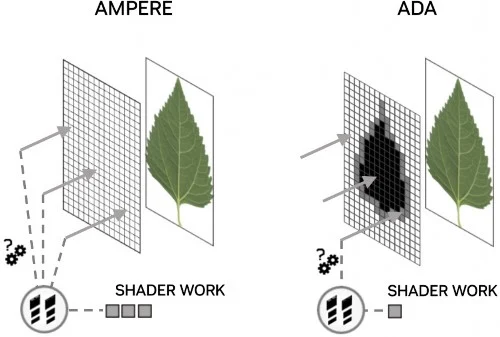
為了更有效處理此類內容,NVIDIA 工程師在第 3 代 RT Core 中添加了 Opacity Micromap Engine,為非不透明物件產生微三角形的虛擬網格,每個微三角形都具有不透明狀態,RT Core 使用該狀態直接解析與非透明三角形的光線交叉點,令 Alpha 場景遍歷性能大幅提升,性能升幅很大程度取決於使用情況,如果場景出現大量投射在 alpha 測試幾何體上的陰影光線時會看到最大的收益。

第 3 代 RT Core 另一個重要提升是添加 Displaced Micro-Mesh Engine,透過將幾何結構換置成微網格,利用 LOD 細節層進行光柵化,相較使用傳統三角幾何光線追蹤處理,不僅擁有更多細節,相較上代 BVH 數據構建速提升了 10 倍, BVH 所需資料容量減少了 20 倍,而且對複雜環境進行光線追踪時,追踪成本緩慢增加,幾何增加 100 倍可能只會增加 1 倍追踪時間。
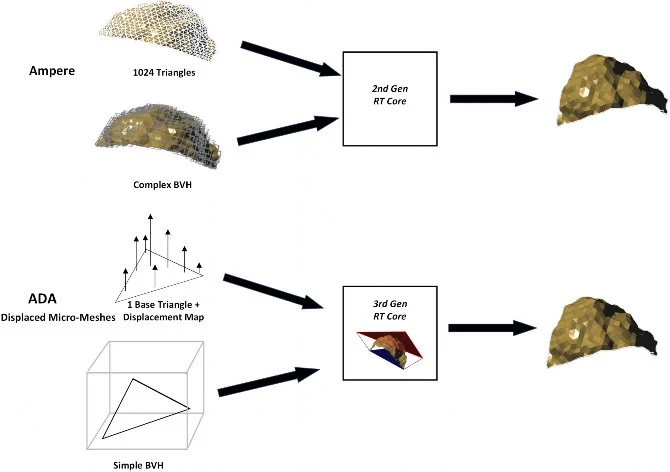
上代 Ampere GPU 可能需要 1024 個三角幾何與複雜的 BVH 結構進行的光線追踪,同樣的效果透過 Displaced Micro-Mesh Engine,只需要 1 個基礎三角形和 1個置換貼圖定義及簡單的 BVH 結構就能完成,可以在不相應增加處理時間或記憶體消耗的情況下實現豐富度的數量級增加。
Shader Execution Reording 技術
為實現遊戲實時光線追踪的逼真渲染,運算時增加了大量的環境中模擬光線運動,同時亦意味著 GPU 原始處理工作量變得越來越不連貫。例如,用於反射、間接照明和半透明效果的二次光線往往會射入,不同的方向並擊中不同的材質,導致二次擊中著色器的有序性和效率較低,不規律性的運算會導致 GPU 的處理單元 SM 的低效使用,因此 NVIDIA 在 Ada Lovelace GPU 架構中加入 Shader Execution Reording 著色器執行重新排序技術,它可以動態地重新排序著色工作以實現更好的執行效率。
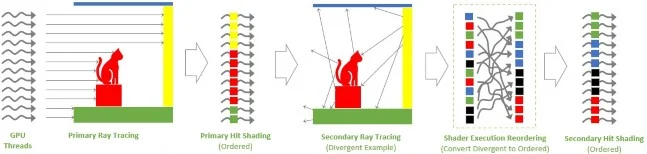
透過 Shader Execution Reording 技術,著色器執行重排序時在光線追踪管道中添加了一個新階段,該階段對二次命中著色進行重新排序和分組,以具有更好地執行局部性,在 Cyperpunk 2077 RT : Overdrive 模式下,啟動 ShaderExecution Reording 技術後性能提升高達 44%,相當驚人。
升級第 4 代 Tensor Cores、全新 DLSS 3 技術

Tensor Cores 是專門為在 AI 和 HPC 應用程序中使用的矩陣乘法和累加數學運算量身定制的高性能運算,可以用於為矩陣計算提供了突破性的性能,這對於深度學習神經網絡訓練和邊緣發生的推理針對遊戲應用層面,Tensor Cores 其中一個重點就是加入全新 DLSS 深度學習超級採樣技術,透過深度神經網路提取渲染場景的多維特徵,並智慧地組合來自多個幀的細節,以建構高品質 3D 影像。與傳統的 AA 技術相比,DLSS 使用更少的輸入樣本,同時避免了透明度和其他復雜場景元素的算法難度。
全新 Ada Lovelace GPU 微架構升級至第 4 代 Tensor Cores 運算單元,相較上代在 FP16、BF16、TF32、INT8 和 INT4 性能提升2 倍以上,新增 FP8 運算能力 AD102 可提供超過 1.3 PetaFLOPS 的張量處理,並且升級至 DLSS 3 技術能透過深度學習使用 AI 產生整幀以大幅提升性能。

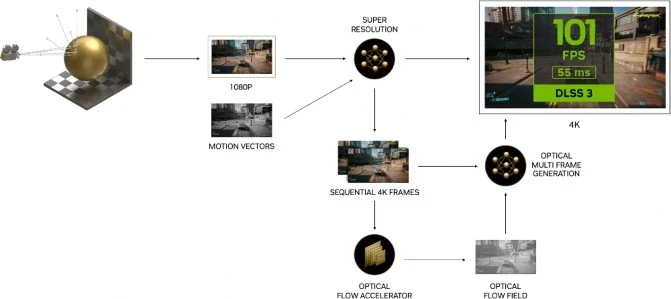
DLSS 3 技術是將先前 DLSS 2 技術,透過 Tensor Cores 運動矢量運算與超解析度技術下,在幀與幀之間加插由以 AI 運算產生的新幀,啟用 DLSS 3 後,AI 將使用 DLSS 超解析度重建第一幀的 3/4,並使用 DLSS AI 幀生成重建整個第二幀,因此 DLSS 3 重建了總顯示像素的 7/8,因此顯著提高了性能。

為了令 AI 幀產生的影像不會出現重影、卡頓和模糊等偽影, ADA Lovelace GPU 新增 Optical Flow Accelerator 光流加速器,它能捕獲粒子、反射、陰影和照明等資訊,DLSS 3 可以計算場景中的一切是如何從一個像素移動到另一個像素的,令遊戲畫面不會出現異常重建。
更重要的是 DLSS 3 可以減低 CPU 造成的性能瓶頸,一些需要 CPU 物理模擬的遊戲例如 Microsoft Flight Simulator,對於 CPU 的性能要求十分高,因此 GPU 經常處於空閒狀態等待指令,DLSS 3 可以將 CPU 密集型遊戲轉換為 GPU 密集型遊戲,因為在 AI 生成幀中全由 GPU 負責,因此在執行 CPU 受限的遊戲,例如那些需要大量物理或涉及大型世界的遊戲, GeForce RTX 40 系列顯卡在相同 CPU 運算能力下,幀速率高達兩倍的幀速率進行渲染。

NVIDIA 指出支援 DLSS 3 的遊戲將會加速上市,當 11/15 GeForce RTX 4080 發售時,將已有 10 款 DLSS 3 遊戲發布:
- 《瘟疫傳說:安魂曲》(A Plague Tale: Requiem)
- 《光明記憶:無限》(Bright Memory: Infinite)
- 《毀滅全人類 2:重新探測》(Destroy All Humans! 2 - Reprobed)
- 《暗影火炬城》(F.I.S.T.: Forged in Shadow Torch)
- 《F1 賽車 22》(F1 22)
- 《逆水寒》(Justice)
- 《生死輪迴》(Loopmancer)
- 《漫威蜘蛛人:重製版》 (Marvel’s Spider-Man Remastered)
- 《微軟模擬飛行》(Microsoft Flight Simulator )
- 《超級人類》(SUPER PEOPLE)
WRC Generations、《極速快感:桀驁不馴》(Need for Speed Unbound) 和 《戰鎚 40K:暗潮》(Warhammer 40,000: Darktide) 在 RTX 4080 推出後不久就會發布,聖誕節前玩家就可暢玩這些 DLSS 3 遊戲。
升級第 8 代 NVENC 編碼引擎

為提升 GPU 編輯性能,AD103 GPU 配搭了兩個第 8 代 NVENC 編碼器,上代 Ampere GPU 只提供 AV1 解碼支援,Ada Lovelace 新增 AV1 編碼支援能力,其編碼效率相較 H.264 編碼器提升了 40%,可支援 8K/60 HDR 或是同時為 4 個 4K/60 HDR 影片編碼運算。
解碼器方面,AD103 GPU 與上代一樣擁有 1 個第 5 代 NVDEC 解碼器,支持 MPEG-2、VC-1、H.264 (AVCHD)、H.265 (HEVC)、VP8、VP9 和 AV1 影片格式的硬體加速影片解碼,支援 8K/60 解析度。
在相同位元率設定下 H.264 (左) 及 AV1 (右) 的畫質表現對比 (建議以 4K 解析度觀看影片)。
由於 AV1 編碼格式比 H.264 格式的編碼效率提升了 40%,變相在相同的位元率設定下 AV1 能提供更高的畫面品質,從上述的比較影片中可以看到左邊的 H.264 編碼格式無法在 8Mbps 頻寬下滿足 4K 60FPS 的內容,出現了大量不連續的小方塊,反之 AV1 在相同位元率下卻仍能提供清晰的動態畫面,兩者可說是高下立判。
NVIDIA GeForce RTX 4080 Founder Edition

收到由 NVIDIA 送測 GeForce RTX 4080 Founder Edition 顯示卡,外觀設計基本上與 RTX 4090 FE 完全一樣,與上代 GeForce RTX 3080 Ti 相似,只有少許細節上的差異,例如金屬外框向內微凹,使用的字體亦有所改動,上手後可以感受到 NVIDIA 對細節的重視。


卡的正面都是霧黑色的散熱鰭片,邊緣採用鈦金色鋁金屬框架,X 框架上刻有 RTX 4080 字樣,沿用軸向式散熱設計,正反兩面各有一個 12cm 散熱風扇,能夠將部份廢熱排向 CPU 區域及直接排出機殼,令機殼內部溫度變得更平均。

GeForce RTX 4080 Founder Edition 相較 RTX 3080 Ti 更龐大,尺寸為 304mm x 137mm x 61mm 基本上小機殼都可以直接略過,用上 Triple Slot 散熱器、雙 12cm 軸向式散熱風扇,頂端 GeForce RTX 字樣在運作時會透出白色 LED 燈效,太炫砲了。

考慮到大部份人安裝顯示卡後,從機殼外看進去只會看到卡背,NVIDIA 將設計反轉了把背板變成正面,並顯示著「RTX 4080」字樣,整張卡所有螺絲孔都用磁吸隱藏了,NVIDIA 真的是從使用者的角度、在細節中作出了考量,難怪那麼多玩家想買 Founder Edition。
NVIDIA PG139 SKU 360

拆開散熱器後,可以看到 GeForce RTX 4080 Founder Edition 採用 PG139 SKU 360 公板設計,與 RTX 3080 Ti PCB 佈局非常相似 ,NVIDIA 刻意將電路板盡量縮小,讓卡身可以鏤空讓軸向式風扇將帶氣流帶到 CPU 區域,12 Layers PCB 設計並經過低阻抗提供訊號及電力傳輸最佳化,同時保留了不俗的超頻性能。

供電設計方面,16 相供電模組設計,其中 13 相負責 GPU 供電、3 相負責 GDDR6X 供電,採用 Monolithic Power Systems MP2891 VRM 控制晶片配搭 Monolithic Power Systems MP86957 70A DrMOS 晶片。
NVIDIA AD103-300 繪圖核心
NVIDIA GeForce RTX 4080 採用了經刪減後的 AD103-300 繪圖核心,採用 TSMC 4N 製程、擁有 459 億個電晶體、Die Size 約為 379mm²,部份單元作出了遮蔽,擁有 7 個 GPC 單元、38 個 TPC 紋理處理群集及 76 個 SM 串流多處理器,具備 9,728 個 CUDA Cores、76 個 RT Cores 及 304 個 Tensor Cores。

核心時脈方面,雖然晶片規模大幅提升但受惠於 TSMC 4N 製程,GPU 時脈相較上代大幅提升,GeForce RTX 4080 FE 預設時脈為 2,205MHz、2,505MHz 加速時脈,支援 GPU Boost 4.0 技術可因應負載自動超頻至更高時脈,最高 TGP 為 320W 比 RTX 3080 Ti 低 30W。
256-bit 16GB GDDR6X 記憶體容量
記憶體方面,GeForce RTX 4080 具備 16GB GDDR6X 記憶體容量及 256-bit 記憶體控制器,採用更高速的 22.4Gbps GDDR6X 顆粒,記憶體頻寬為 716.8GB/s 雖然比 RTX 3080 Ti 少,但擁有更高的 64MB L2 Cache 容量,以滿足更高解析度、更複雜的著色器渲染運算畫面。

採用了8 顆 Micron D8BZF GDDR6X 顆粒,編號為 MT61K512M32KPA-24,其最高速度為 24Gbps,因此擁有一定記憶體超頻空間 ,每顆單顆容量為 16Gbit (2GB),總容量為 16GB 繪圖記憶體容量。
Triple Slot 軸向式散熱器設計



NVIDIA GeForce RTX 4080 FE 沿用軸向式散熱設計,設計與 RTX 3090 Ti 相同只是變得更巨大了,Triple Slot 雙 12 cm 風扇,GPU / VRM 及 GDDR6X 記憶體位置被巨型 Vapor Chamber 均熱板覆蓋,再透過 6 支導熱管傳導致另一組散熱鰭片,搭配兩顆 12cm 風扇,其中一顆反葉設計讓冷空間穿過卡身未端排向 CPU 區域。
採用 12VHPWR 供電

供電方面,GeForce RTX 4080 Founder Edition 採用 12 +4 Pin 的 12VHPWR 電源接頭,單一接頭最高可提供 600W 供電,由於原生支援 12VHPWR 連接線的電源供應器 太少,NVIDIA 隨產品附上 PCIe 8Pin to 12VHPWR 轉接線,由於 RTX 4080 的 TGP 只有 320W,因此附的轉接線只需接上 3 個 PCIe 8 Pin 即可,要記住轉接線有物理限制,在其觸點開始磨損之前可以插拔最大次數 30 次,同時不要過份彎曲使用否則可能會導致短路。
2 個 8K@60Hz HDR 顯示輸出

NVIDIA GeForce RTX 4080 Founder Edition 提供了 3 組 Display Port 1.4a + DSC 及 2 組 HDMI 2.1 影像輸出,兩種輸出介面皆可提供最高 4K@240Hz 或 8K@60Hz 12bit HDR 解析度輸出,支援 VEGA DSC 1.2 無損壓縮顯示功能,單卡能提供最高 2 個 8K@60Hz HDR 顯示輸出,或是組合 2 組 DisplayPort 提供單一 8K@120Hz HDR 輸出。
效能測試

編輯部收到由 NVIDIA 送測的 GeForce RTX 4080 Founder Edition 顯示卡樣品,同時亦找來 GeForce RTX 3080 Ti Founder Edition 作對比測試,以了解新一代 GeForce RTX 4080 的效能水準,此次測試使用由 FSP 提供的 Hydro PTM Pro 1000W 電源供應器。


時脈方面,NVIDIA GeForce RTX 4080 FE 預設核心時脈為 2,205MHz、2,505MHz 加速時脈,支援 GPU Boost 4.0 技術最高可達 2,745MHz。
| 處理器 | Intel Core i9-12900K |
|---|---|
| 主機板 | ASROCK Z690 AQUA OC |
| 顯示卡 | NVIDIA GeForce RTX 3080 Ti FE、NVIDIA GeForce RTX 3090 Ti FE、NVIDIA GeForce RTX 4080 FE、NVIDIA GeForce RTX 4090 FE、AMD Radeon RX 6950 XT |
| 記憶體 | G.SKILL DDR5-6000 CL30-38-38-39 16GB x 2 @1.35V |
| 作業系統 | Windows 11 Professional 22H2 |
| 驅動程式 | NVIDIA GeForce Driver 526.72 WHQL |

散熱方面,NVIDIA GeForce RTX 4080 FE 在約 25°C 的室溫環境下閒置約 30分鐘,GPU 溫度維持在 36°C。接著採用 Furmark 進行 3D 負載測試,將 GPU 完全負載 30 分鐘後,溫度則提升至 63°C 的,GPU 時脈保持在 2,370MHz,在 Full-Load 時的時脈相較 NVIDIA GeForce RTX 3080 Ti FE 高了近 1GHz。
3DMARK
3DMARK 作為最廣泛的 3D 性能基準測試,性能對比結果當然不可缺少,根據測試顯示 GeForce RTX 4080 遊戲性能相較上代產品有明顯提升,性能甚至比上代旗艦相較 RTX 3090 Ti 更高,但不難發現當解析度越來越高,它與 RTX 3090 Ti 的差距就會拉近一點,始終 384bit vs 256bit 記憶體介面啊,3DMark Fire Strike 與 Time Spy 要完勝是沒有問題。
| FireStrike | FireStrike Extreme | FireStrike Ultra | Time Spy | Time Spy Extreme | |
|---|---|---|---|---|---|
| GeForce RTX 3080 Ti | 33667 | 22014 | 12215 | 17709 | 8996 |
| Radeon RX 6950 XT | 41745 | 26992 | 14819 | 19457 | 9290 |
| GeForce RTX 3090 Ti | 36189 | 24486 | 14225 | 19555 | 10046 |
| GeForce RTX 4080 | 47169 | 32074 | 16282 | 26686 | 13087 |
| GeForce RTX 4090 | 54895 | 39440 | 24946 | 33100 | 16861 |
3DMark Ray-Tracing 測試
3DMark Port Royal 是首款針對即時光線追蹤所設計的測試工具,支援 Microsoft DirectX Raytracing 技術,讓玩家測試不同顯卡對於光線追蹤的效能,擁有第 3 代 RT Core 的 RTX 4080 絕對是神一般的存在,測試得分為 17908 仍能大幅壓倒 RTX 3090 Ti 與 RX 6950 XT。
| PR | |
|---|---|
| GeForce RTX 3080 Ti | 12657 |
| Radeon RX 6950 XT | 10789 |
| GeForce RTX 3090 Ti | 14771 |
| GeForce RTX 4080 | 17908 |
| GeForce RTX 4090 | 25995 |
遊戲效能測試
以下的遊戲測試除另外註明外,全部皆以 3840 x 2160 解析度全螢幕執行,畫質皆設定為最高品質,若遊戲支援光線追蹤技術則同時將光追品質全開。而 DLSS 方面則統一使用 Performance 設定,當中 GeForce RTX 4090 亦會啟用 DLSS 3 中新增的 Frame Generation 技術。
A Plague Tale : Requiem 瘟疫傳說:安魂曲
| 4K + DLSS Off | 4K + DLSS On | |
|---|---|---|
| GeForce RTX 3080 Ti | 42.1 | 78.1 |
| GeForce RTX 3090 Ti | 44.9 | 80.4 |
| GeForce RTX 4080 | 55.8 | 138.2 |
| GeForce RTX 4090 | 78.5 | 174.9 |
Cyberpunk 2077 (New RT Overdrive)
| 4K RT + DLSS OFF | 4K RT + DLSS On | |
|---|---|---|
| GeForce RTX 3080 Ti | 21.8 | 59.4 |
| GeForce RTX 3090 Ti | 24.1 | 66.4 |
| GeForce RTX 4080 | 30.1 | 114.7 |
| GeForce RTX 4090 | 43.2 | 149.8 |
Destroy All Humans! 2 – Reprobed
| 4K + DLSS Off | 4K + DLSS On | |
|---|---|---|
| GeForce RTX 3080 Ti | 81.6 | 158.9 |
| GeForce RTX 3090 Ti | 83.4 | 161.2 |
| GeForce RTX 4080 | 94.1 | 177.1 |
| GeForce RTX 4090 | 119.6 | 229.3 |
F1 22
| 4K RT + DLSS OFF | 4K RT + DLSS ON | |
|---|---|---|
| GeForce RTX 3080 Ti | 54 | 127 |
| GeForce RTX 3090 Ti | 60 | 137 |
| GeForce RTX 4080 | 69 | 180 |
| GeForce RTX 4090 | 96 | 232 |
Justice Online 逆水寒
| 4K RT + DLSS Off | 4K RT + DLSS On | |
|---|---|---|
| GeForce RTX 3080 Ti | 5.4 | 19.2 |
| GeForce RTX 3090 Ti | 7.9 | 26.6 |
| GeForce RTX 4080 | 40.2 | 76.2 |
| GeForce RTX 4090 | 51.4 | 110.7 |
Microsoft Flight Simulator 微軟模擬飛行
| 4K + DLSS OFF | 4K + DLSS ON | |
|---|---|---|
| GeForce RTX 3080 Ti | 47.2 | 69.1 |
| GeForce RTX 3090 Ti | 54.1 | 81.7 |
| GeForce RTX 4080 | 65.9 | 150.9 |
| GeForce RTX 4090 | 77.4 | 169.9 |
Tom Clancy's Rainbow Six Siege 虹彩六號:圍攻行動
| 1080P | 2K | 4K | |
|---|---|---|---|
| GeForce RTX 3080 Ti | 595 | 506 | 304 |
| GeForce RTX 3090 Ti | 598 | 513 | 321 |
| GeForce RTX 4080 | 610 | 586 | 395 |
| GeForce RTX 4090 | 613 | 586 | 517 |
Tower of Fantasy
| 4K + DLSS Off | 4K + DLSS On | |
|---|---|---|
| GeForce RTX 3080 Ti | 28.9 | 88.6 |
| GeForce RTX 3090 Ti | 34.2 | 107.6 |
| GeForce RTX 4080 | 43.2 | 145.5 |
| GeForce RTX 4090 | 59.2 | 190.5 |
Unity Enemy Demo
| 4K + DLSS Off | 4K + DLSS On | |
|---|---|---|
| GeForce RTX 3080 Ti | 15.8 | 33.54 |
| GeForce RTX 3090 Ti | 17.4 | 42.6 |
| GeForce RTX 4080 | 22.7 | 77.6 |
| GeForce RTX 4090 | 30.1 | 97.3 |
Unreal Engine 5 : Lyra Demo
| 4K RT + DLSS Off | 4K RT + DLSS On | |
|---|---|---|
| GeForce RTX 3080 Ti | 53 | 104.2 |
| GeForce RTX 3090 Ti | 58.1 | 114.3 |
| GeForce RTX 4080 | 72.4 | 160.6 |
| GeForce RTX 4090 | 90.7 | 197.2 |
DaVinci Resolve Studio 18 硬體編碼效能測試
除了遊戲性能的提升外,對於一眾創作者來說顯示卡的硬體的編解碼速度同樣重要。NVIDIA GeForce RTX 4080 就擁有兩個第 8 代 NVENC 編碼器,不但新增了 AV1 編碼能力,在 H.264 及 H.265 編碼速度上亦有明顯的提升。
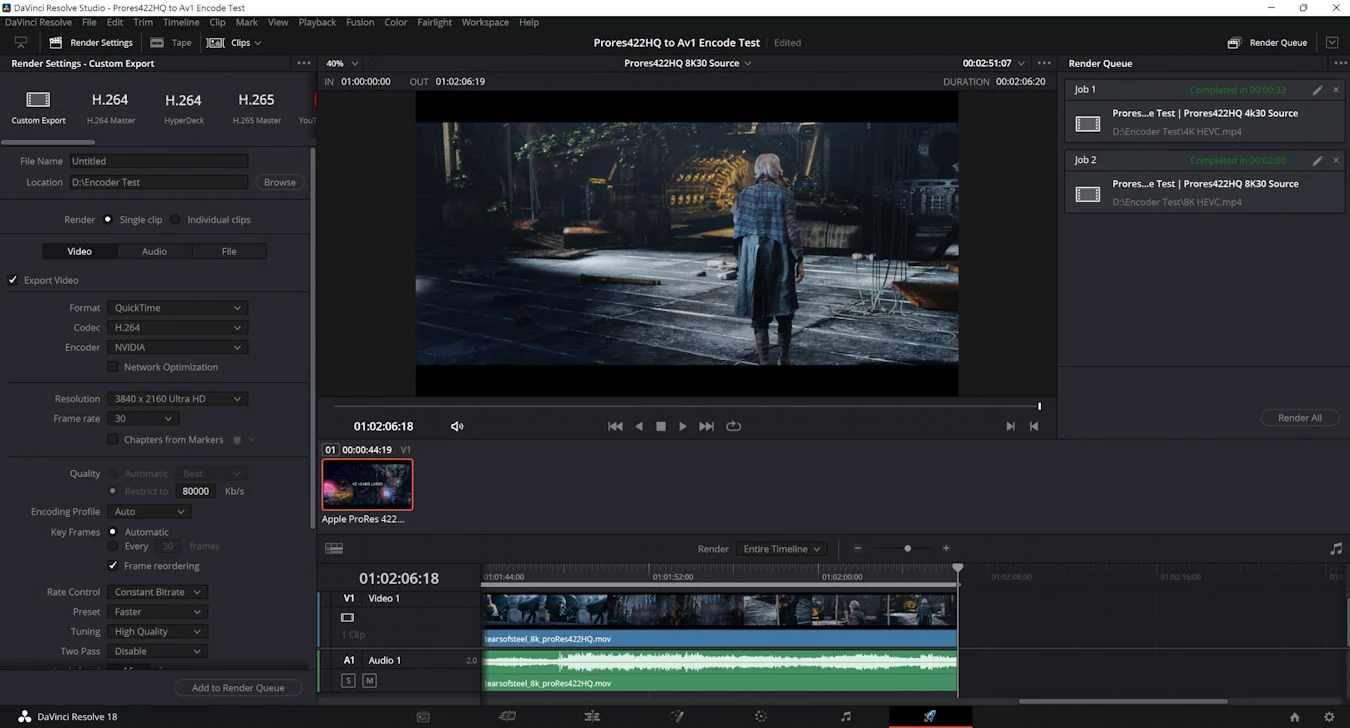

測試採用 DaVinci Resolve Studio 18 影片剪輯軟體,分別使用 GeForce RTX 4080 及 RTX 3080 Ti 以 H.265 及 AV1 編碼格式各輸出一段 4K 及 8K 的影片,結果顯示 RTX 4080 的 H.265 編碼速度比 RTX 3090 Ti 快了一倍以上,而在 AV1 編碼上更比 RTX 3080 Ti 快了無限倍,因為 RTX 3080 Ti 根本不支援 AV1 編碼。
| 測試項目 | GeForce RTX 3080 Ti FE | GeForce RTX 4080 FE |
|---|---|---|
| 4K30 - H.265 | 00:33 | 00:13 |
| 8K30 - H.265 | 02:00 | 00:56 |
| 4K30 - AV1 | 不支援 | 00:13 |
| 8K30 - AV1 | 不支援 | 00:56 |
編輯評語
NVIDIA GeForce RTX 4080 作為效能級顯示卡,性能大致相較上代 RTX 3080 Ti 快 30 至 90%,並超越了上代旗艦卡,如果啟動 DLSS 3 技術效能提升將會更高,整體表現相當不錯,現在等待它的是對手 AMD 即將在 12 月發佈 Radeon RX 7900 XTX 的考驗,如果你是 N 粉那麼 RTX 4080 可以買,如果你並沒有信仰的話,不妨多等幾個禮拜。
以上內容及測試數據為 HKEPC 獨家授權給 UNIKO's Hardware 編譯







