

NVIDIA GeForce RTX 3080 FE 顯示卡率先解禁效能,採用 NVIDIA 第 2 代 RTX 架構,強化的 RT 核心、 Tensor 核心、全新串流多處理器,以及 19Gbps 的 10GB GDDR6X 記憶體。官方宣稱這是有史以來最大的世代躍進,GeForce RTX 3080 更多技術和黑科技詳細說明都在文章裡面,遊戲實測又是如何呢?讓我們繼續看下去~
NVIDIA GeForce RTX 30 系列登場

NVIDIA 16 日正式發佈首款「Ampere」安培 GPU 微架構產品、核心代號為「GA102」的效能級「GeForce RTX 3080」,號稱是 NVIDIA GPU 史上最大的架構躍進,採用 NVIDIA 的第二代 RTX 架構 Ampere 安培,配備第二代 2 倍輸送量的 RT 核心、最高 2 倍輸送量的第三代 Tensor 核心、全新 2 倍 FP32 輸送量 SM 串流多處理器及 GDDR6X 記憶體。
整個 NVIDIA Ampere 安培架構都是為提高效率而設計的,從定制流程設計到電路設計,邏輯設計,封裝,RAM,電源和散熱設計,再到 PCB 設計以及軟體和算法,為 PC 遊戲帶來全新的領域。

除了 GeForce RTX 3080 新卡,NVIDIA 將會在 9 月 24 日再發佈旗艦級 GeForce RTX 3090,同樣基於 GA102 繪圖核心,高達 10,496 CUDA 核心、24GB GDDR6X,啟用 DLSS 8K 模式後,可以在大部份遊戲中以 8K @ 60Hz 執行遊戲,售價為 USD$1,499。
10 月 15 日將會再推出效能級 GeForce RTX 3070,採用 GA104 繪圖核心、內建 5,888 CUDA 核心、8GB GDDR6,提供可與 NVIDIA 上一代旗艦 GeForce RTX 2080 Ti 媲美的性能,售價僅 USD$499,幫發布會前才買 RTX 2080 Ti 的玩家拍拍。
SAMSUNG 8nm 制程、 NVIDIA GA102 繪圖核心
NVIDIA GA102 繪圖核心基於全新 Ampere 安培 GPU 微架構,並用於 GeForce RTX 3080 與 GeForce RTX 3090 產品之中,性能的提升主要來自 FP32 運算單元提升了 1 倍、升級第 2 代 RT 核心、升級第 3 代 Tensor 核心,經改良的 ROP 單元及換上更高速的 GDDR6X 記憶體,與上代 Turing 圖靈 GPU 微架構比較,傳統光柵圖形運算提高了 1.7 倍,同時在光線追蹤性能上提升近 2 倍。

「GeForce RTX 3080」採用「TU104-200-A1」繪圖核心,採用 8nm NVIDIA Custom 制程、三星代工,擁有 283 億個電晶體、Die Size 約為 628mm²,完整的 GA102 晶片內建 7 個 GPC 單元、42 個 TPC 紋理處理群集及 84 個 SM 串流多處理器,增至 10,752 個 CUDA 核心、84 個 RT 核心及 336 個 Tensor 核心。

不過,「GeForce RTX 3080」部份單元作出了屏蔽,刪減至只有 6 個 GPC 單、34 個 TPC 紋理處理群集及 68 個 SM 串流多處理器,具備 8,702 個 CUDA 核心、68 個 RT 核心及 272 個 Tensor 核心。
核心時脈方面,雖然晶片規模大幅提升但時脈仍能保持於高水平,GeForce RTX 3080 預設時脈為 1,440MHz 基礎時脈、1,710 MHz 加速時脈,最高 TDP 為 320W。此外,「GeForce RTX 3080」改用了全新 GDDR6X 記憶體顆粒,雖然記憶體時脈只有 1,188MHz,傳輸速度卻高達 19Gbps,加上 320 bit 記憶體頻寬介面,令總頻寬提升 760GB/s。
| Graphics Card | GeForce RTX 2080 Founders Edition |
GeForce RTX 2080 Super Founders Edition |
GeForce RTX 3080 10 GB Founders Edition |
|---|---|---|---|
| GPU Codename | TU104 | TU104 | GA102 |
| GPU Architecture | NVIDIA Turing | NVIDIA Turing | NVIDIA Ampere |
| GPCs | 6 | 6 | 6 |
| TPCs | 23 | 24 | 34 |
| SMs | 46 | 48 | 68 |
| CUDA Cores / SM | 64 | 64 | 128 |
| CUDA Cores / GPU | 2944 | 3072 | 8704 |
| Tensor Cores / SM | 8 (2nd Gen) | 8 (2nd Gen) | 4 (3rd Gen) |
| Tensor Cores / GPU | 368 | 384 (2nd Gen) | 272 (3rd Gen) |
| RT Cores | 46 (1st Gen) | 48 (1st Gen) | 68 (2nd Gen) |
| GPU Boost Clock (MHz) | 1800 | 1815 | 1710 |
| Peak FP32 TFLOPS (non-Tensor)1 | 10.6 | 11.2 | 29.8 |
| Peak FP16 TFLOPS (non-Tensor)1 | 21.2 | 22.3 | 29.8 |
| Peak BF16 TFLOPS (non-Tensor)1 | NA | NA | 29.8 |
| Peak INT32 TOPS (non-Tensor)1,3 | 10.6 | 11.2 | 14.9 |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate1 |
84.8 | 89.2 | 119/2382 |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate1 |
42.4 | 44.6 | 59.5/1192 |
| Peak BF16 Tensor TFLOPS with FP32 Accumulate1 |
NA | NA | 59.5/1192 |
| Peak TF32 Tensor TFLOPS1 | NA | NA | 29.8/59.52 |
| Peak INT8 Tensor TOPS1 | 169.6 | 178.4 | 238/4762 |
| Peak INT4 Tensor TOPS1 | 339.1 | 356.8 | 476/9522 |
| Frame Buffer Memory Size and Type | 8192 MB GDDR6 | 8192 MB GDDR6 | 10240 MB GDDR6X |
| Memory Interface | 256-bit | 256-bit | 320-bit |
| Memory Clock (Data Rate) | 14 Gbps | 15.5 Gbps | 19 Gbps |
| Memory Bandwidth | 448 GB/sec | 496 GB/sec | 760 GB/sec |
| ROPs | 64 | 64 | 96 |
| Pixel Fill-rate (Gigapixels/sec) | 115.2 | 116.2 | 164.2 |
| Texture Units | 184 | 192 | 272 |
| Texel Fill-rate (Gigatexels/sec) | 331.2 | 348.5 | 465 |
| L1 Data Cache/SharedMemory | 4416 KB | 4608 KB | 8704 KB |
經改良的 Ampere SM 架構
NVIDIA「GA102」繪圖核心採用全新「Ampere」安培 GPU 微架構,其中一個主要改良是 SM 串流多處理群的設計,上代 Turing 圖靈 SM 首次在 SM 模組內增設 INT32 運算單元,每個 SM 模組內共有 64 個 FP32 CUDA、64 個 INT32 運算單元,每個 SM 分區均擁有 1 條 FP 與 1 條 INT 數據路徑,因此每個 Turing 圖靈 SM 每個週期可處理 64 個 FP32 及 64 個 INT32 操作。
現代遊戲負載擁有更廣泛的運算需求,許多工作負載混合使用 FP32 運算指令 (例如 FFMA、FADD 及 FMUL),同時亦具備簡單的整數指令,例如尋址、加法、浮點比較,以為最大值 / 最小值等獲取處理結果等工作,現代遊戲的指令平例 FP 與 INT 約為100:36,因此 Ampere 安培 GPU 針對 FP32 與 INT32 運算加入更具效率的調度。

全新 Ampere 安培 SM 設計將 SM 模組改為 128 個 FP32 CUDA 運算單元,其中一半兼備 INT32 運算能力,同時將每個 SM 分區的 2 組數據路徑均可用於 FP 運算,但其中 1 組可調度用於 INT 運算,因此每個 Ampere 安培 SM 每個週期可處理 128 個 FP32,或調整至 64 個 FP32、64 個 INT32 操作。
更改經後 Ampere 安培可將 FP32 運算能力提升 1 倍,面對不同的運算需求時更有彈性、更具效率,尤其在啟用 Ray Tracing 光線追蹤後會有更多的 FP32 運算操作,因此 Ampere 安培 GPU 在光追性能表現提升會更為明顯。
此外,Ampere 安培 SM 繼續支援由 Turning 圖靈 GPU 微架構開始加入的雙速 FP16 (HFMA) 運算操作,一般的 FP16 運算會交由 Tensor 核心處理。
更大 L1 Data Cache 設計
全新 Ampere 安培 SM 沿用了 L1 Cache、Texture Cache 及 Share Memory 整合的統一共享緩存設計,每個 SM 的 L1 Cache 容量由 96KB 提升至128KB,較上代提升了 33%,同時提供更具彈性的分割,例如在純運算模式下, Ampere 安培 SM 的 L1 Cache 新增 6 種不同配置。
| L1 | Share Memory |
|---|---|
| 128KB | 0KB |
| 120KB | 8KB |
| 112KB | 16KB |
| 96KB | 32KB |
| 64KB | 64KB |
| 28KB | 100KB |
如果是圖形工作或混合運算模式下,Ampere 安培 SM 則會將 L1 Cache 分配為 64 KB Texture Cache (較上代增加 1 倍)、48KB Share Memory及 16KB L1 Cache 保用於 Graphics Pipeline 運算用途。
除了 L1 Cache 容量增加外,L1 Cache的頻寬亦較上代 Tuning 圖靈 SM 提升了 1 倍,由於上代每個週期 64 bytes/clock 提升至 128 bytes/clock,舉例 GeForce RTX 2080 Super 的 L1 Cache 總頻寬為 116GB/s,GeForce RTX 3080 則大幅提升至 219GB/s,此舉簡化了編程所需的調度優化需求,相較上代 Turing 圖靈的 L1 Cache 頻寬提升達 1 倍並大幅降低了延遲。
升級第 2 代光線追蹤引擎 !!

Ray Tracing 光線追蹤技術是一種密集型渲染技術,可以逼真地模擬場景及物件的光線,實時以物理方式渲染正確的反射、折射、陰影及間接照明效果。過去的 GPU 架構並無法對遊戲及圖形進行複雜的實時光線追踪處理,NVIDIA 經過過 10 年的研究及開發,終於在上代 GeForce RTX 20 的 Turing 圖靈 GPU 微架構中加入硬體光線追踪加速引擎 —「RT 核心」,結合 NVIDIA RTX 軟體引擎,實現逼真的實時光線場景效果。
這一代 GeForce RTX 30 系列的「Ampere」安培 GPU 升級了第二代的「RT 核心」,上代在 BVH 遍歷與射線三角交測運算能力,效能是第一代「RT 核心」的 2 倍,以往 Turning 圖靈 SM 在光線追蹤運算時不能同時執行 Graphics 或 Compute 運算,這一代 Ampere 安培 SM 強化了異步運算能力,當執行光線追蹤運算時可同步進行 Graphics 或 Compute 運算,令光線追蹤的遊戲執行效率大大提升。

如果單純用 CUDA 核心運算需要 51ms (~20fps),如果交由 RT 核心運算可下降至 20ms (~50fps),如果啟用 DLSS 將部份運算交由 Tensor 核心處理器則可減至 12ms (~83fps)。

單純用 CUDA 核心已降至 37ms、交由 RT 核心運算可降至 11ms,如果啟動了 DLSS 將將部份運算交由 Tensor 核心處理器則可減至 6.7ms (~150fps),光線追蹤性能提升非常明顯。
全新第 3 代 Tensor 核心運算單元
上代 Turing 圖靈 GPU 採用第二代 Tensor 核心運算單元,這是專門用於執行向量及矩陣運算的運算單元,包括 INT8 及 INT4 精度的函數運算,以及更高精度的 FP16 運算工作,主要用於深度學習神經網絡運算、推理運算、矩陣運算等,提供更佳的硬體加速能力。
針對遊戲應用層面,Tensor 核心其中一個重點就是加入全新 DLSS 深度學習超級採樣技術,透過深度神經網絡提取渲染場景的多維特徵,並智能地組合來自多個幀的細節,以構建高質量 3D 影像。與傳統的 AA 技術相比,DLSS 使用更少的輸入樣本,同時避免了透明度和其他復雜場景元素的算法難度。
| TU102 GPU | GA102 GPU | |
|---|---|---|
| GPU Architecture | NVIDIA Turing | NVIDIA Ampere |
| Tensor Cores per SM | 8 | 4 |
| FP16 FMA operations per Tensor Core | 64 | Dense: 128 Sparse: 256 |
| Total FP16 FMA operations per SM | 512 | Dense: 512 Sparse: 1024 |
全新 Ampere 安培 GPU 微架構升級至第 3 代 Tensor 核心運算單元,加入了更多不同類型的數據運算模式,例如加入新的稀疏性運算、TF32 及 BFloat 16 等新精度模式,同時在矩陣乘法的速度提高了 2 倍,同時 NVIDIA 針對每個 SM 內的 Tensor 核心數目作出了重組,減少了一半 Tensor 核心的數目,但每個 Tensor 核心運算能力變得更為強大。

新一代 GeForce RTX 3080 的 Tensor 核心能提供高達 119 TLOPS 的 FP16 累計,如果啟用了稀疏性運算下則可提升至 238 TFLOPS, INT8 及 INT4 精度的函數運算可達 238 與 476 TFLOPS,如果啟用了稀疏性運算後則可提升 1 倍,與 RTX 2080 Super 相較的話,其張量運算吞吐量提高了 2.7 倍。

由於 Amprer 安培 GPU 微架構的 Tensor 核心運算能力大幅提升,啟動 DLSS 深度學習超級採樣的性能提升將會更為明顯,利用深度神經網絡提取渲染場景的多維特徵,並智能地組合多個幀中的細節,以構建看起來與原始圖像非常接近的結果,甚至在更高的分辨率中提升更佳的質素,圖上為 Watch Dog 遊戲分別在 1080p、4K 及 8K DLSS 下的畫質對比,可以看到透過第 3 代 Tensor 核心及全新 9 倍超分率縮放因子,使得遊戲在 8K 下再加上光線追蹤進行遊戲變成可能。
全新 GDDR6X 記憶體控制器

記憶體子系統對性能表現絕對是至關重要,因此 Ampere 安培 GPU 微架構特別針對記憶體控制器、Cache 緩存設計作出改良,以增加記憶體頻寬及減少讀取延遲,其中一大改進是全新 GDDR6X 記憶體控制器,配合更高的 GDDR6X 記憶體顆粒,以滿足功能更強大的著色器與更加複雜的渲染技術。
GeForce RTX 30 系列是首個應用 GDDR6X 技術的 GPU 產品,它並不是單純提供晶片時脈而是透過全新的 4-Level PAM4 四級脈衝訊號,透過多級訊令技術可以在單一週期傳輸 2 筆資料,相較舊有 GDDR6 採用的 2-Level NRZ 技術,在同時脈下頻寬提升 1 倍。

PAM4 並不是直接傳輸兩位 2 進制訊號,而是使用了 4個不同的電壓水平,每個電壓電平相差 250mV,每個電平代表著 2 個數據位,透過電壓差提供 00、01、10 或 11 數據。

為了解決 PAM4 技術的 SNR 訊噪問題,GDDR6X 提供了全新 MTA 編碼方案 MTA,防止訊號從最高電平轉換到最低電平,反之亦然,從而提高了接口 SNR 。這是通過使每個引腳的一部分數據脈衝串在編碼引腳上傳輸的字節中的一部分 (時間交織),然後使用明智選擇的代碼字將數據脈衝串的其餘部分映射到一個沒有最大躍遷的序列來實現的。最後,封裝和 PCB 設計均需要重新設計,並進行全面的信號和電源完整性分析,以實現更高的數據速度。
全新 GeForce RTX 3080 支援最高 19Gbps GDDR6X 記憶體、320-bit 記憶體介面,提供高達 760GB/s 記憶體頻寬,相較舊有 GeForce RTX 2080 Super 的 496GB/s 頻寬提高了 53%。
更大、更快的 L2 Cache
| GeForce RTX 3080 | GeForce RTX 2080 Super | |
|---|---|---|
| Memory Interface | 320-bits | 256-bits |
| Memory Type | GDDR6X | GDDR6 |
| Memory Size | 10,240MB | 8,192MB |
| Memory Clock | 19Gbps | 15.5Gbps |
| Memory Bandwidth | 760GB/s | 496GB/s |
| ROPS | 96 | 64 |
| L2 Cache | 5,120KB | 4,096KB |
| Register File | 17,408KB | 11,776KB |
除了全新的 GDDR6X 記憶體控制器外,「Ampere」安培 GPU 同時改良了 L2 Cache 緩存設計,上代「GeForce RTX 2080 Super」繪圖核心提供 4MB L2 Cache 容量,全新「GeForce RTX 3080」繪圖核心提升至 5MB L2 Cache, Register Files 容量亦由 12,288 KB 提供至 17,408KB,
ROP 設計方面,「Ampere」安培 GPU 設計與上代「Turing」圖靈大致相同,每個 ROP 模組內包含 8 個 ROP 運單元,每個 ROP 單元單一週期可處理一個單色樣本,「GeForce RTX 3080」繪圖核心共有 12 個 ROP 模組、合共 96 個 ROP 運算單元。
RTX I/O︰GPU 直讀 PCIe SSD !! 性能 100 倍

NVIDIA Ampere 微架構加入全新 RTX I/O 功能,可以讓 PCIe SSD 性能提升 100 倍,可望降低遊戲運算等待 I/O 讀取的 Overhead,配合明年 Windows 10 新增 DirectStorage API 。
NVIDIA RTX I/O 技術是為了配合明天 Microsoft Windows 10 的 DirectStorage API 而生,它可以實現 GPU 直接讀取 PCIe SSD 內的資料並實時進行資料解壓縮,它可以將 CPU 運算工作讓 GPU 分擔,實現更低延遲的遊戲新體驗。
以往,GPU 讀取遊戲資料都需要交由 CPU 處理器向 SSD 讀取,放進系統記憶體再由 GPU 讀取,這樣會出現嚴重 I/O 延遲並且非常佔用 CPU 資料,以 PCIe Gen 4 SSD 最高頻寬 7GB/s 為例,大約需要佔用 2 個 CPU Cores 的資源,如果要加入無損壓縮技術的話,就需要 24 CPU Cores 完全滿載才能應付,根本無法使用。

使用了 RTX I/O 技術後,GPU 不再需要向 CPU 提出 I/O 讀取要求,只需要透過 Microsoft DirectStorage API 直接經 PCIe 讀取 SSD 資料,處理 1:2 高質量紋理無損壓縮可以交由 GPU 負責,令 PCIe Gen 4 的可效頻寬由 7GB/s 提升至 14GB/s,但只需要佔用約 0.5 CPU 核心資源,RTX IO 將數十個 CPU 內核的工作分擔給GeForce RTX GPU,從而大幅提升遊戲 FPS 幀數,實現了近乎實時的遊戲載入,
借助 RTX I/O 技術無損壓縮,能有效降低開放性世界的遊戲體積,無需佔用太多的 SSD 空間、減少遊戲下載的時間從而使遊戲玩家可以在SSD上存儲更多遊戲,同時還可以提高性能,值得期待。
升級 HDMI 2.1、支援 8K @ 60Hz HDR

為迎接 8K 輸出時代,全新「GA102」繪圖核心更新了顯示輸出引擎,除了支援 DisplayPort 1.4a 接口,同時亦將 HDMI 升級 2.1 版本,無論是 DisplayPort 或是 HDMI 介面均可以提供 8K @ 60Hz 12bit HDR 解析度輸出,這是 4K 像素的 4 倍頻寬需求,更支援 VEGA DSC 1.2 技術提供更高壓縮的無損顯示功能,並且單卡可以提供最高 2 個 8K @ 60Hz 顯示輸出,或是採用 2 組 DisplayPort 接線提供 1 個 8K @120Hz 輸出。
| Bandwidth/Link | Total Bandwidth | Max Resolution | |
|---|---|---|---|
| DisplayPort 1.4a | 8.1Gbps | 32.4Gbps | 4K@240Hz HDR 8K@60Hz HDR |
| HDMI 2.1 | 8.1Gbps | 48Gbps | 4K@240Hz HDR 8K@60Hz HDR |
第 5 代 NVDEC、新增 AV1 硬體解碼
全新「GA102」繪圖核心包含了第 5 代 NVDEC 影像解碼器及第 7 代 NVENC 影像編碼器,可以在 Windows、Linux 平台下提供 MPEG-2 / VP8 / VP9 / VC-1 / H.264 (AVCHD) / H.265 (HEVC) ,更重要是追加了全新的 AV1 解碼能力,NVIDIA 是全球第一家在 GPU 加入硬件 AV1 解碼的廠商。

AV1 是 AOM(開放媒體聯盟)開發的一種免版稅的開放視頻編碼格式,主要用於 Internet 上的視頻傳輸,包括了 Youtube 將會在 8K 中採用 AV1 格式,GA10x GPU是最早提供 AV1 硬件解碼支援,最高提供 8K @ 60Hz 播放能力,與H.264、HEVC 和 VP9 等現有編解碼器相比,AV1 提供了更好的壓縮和質量,必然會成為視頻平台和瀏覽器採用的未來標準規格,與H.264相比,AV1 約可節省 50-55% bitrate。

此外,「GA102」具備第 7 代 NVENC 影像編碼器,這與 Turing 圖靈 GPU 所用的一樣,它是獨立的硬體並不會佔用任何 GPU 其他運算單元資源,當進行遊戲或 GPU 運算時,將視頻編碼卸載到 NVENC 影像編碼器,GPU的圖形引擎可以專心於遊戲渲染,在不使用 CPU 的情況下以高質量和超低延遲對遊戲和應用程序進行編碼和流傳輸,提供高質量編碼用於存檔及直播用,更重要較 CPU 編碼功耗更低、更省電,最高支 HEVC 8K @60Hz 編碼能力。

拿在手上可以感受到 NVIDIA 對精雕細節的重視,卡的正面都是霧黑色的散熱鰭片,邊緣採用鈦金色鋁金屬框架,並且印有 RTX 3080 字樣,創新的軸向式散熱設計,正反兩面各有一個 9cm 散熱風扇,能夠將部份廢熱排向 CPU 區域及直接排出機殼,令機殼內部溫度變得更平均,非常創新。


NVIDIA PG132 -10 公板設計
拆開散熱器,可以看到「GeForce RTX 3080」創始版採用 PG132-10 公板設計,NVIDIA 刻意將電路板盡量縮小,讓卡身可以褸空讓軸向式風扇將帶氣流帶到 CPU 區域,12 Layers PCB 設計並經過低阻抗提供訊號及電力傳輸優化,同時保留了不俗的超頻性能。

NVIDIA GA102-200 繪圖核心
NVIDIA「GeForce RTX 3080」採用的經刪減後的「GA102-200」繪圖核心,擁有 283 億個電晶體、Die Size 約為 628mm²,部份單元作出了屏蔽,刪減至只有 6 個 GPC 單、34 個 TPC 紋理處理群集及 68 個 SM 串流多處理器,具備 8,702 個 CUDA 核心、68 個 RT 核心及 272 個 Tensor 核心。

核心時脈方面,雖然晶片規模大幅提升但時脈仍能保持於高水平,GeForce RTX 3080 預設時脈為 1,440MHz 基礎時脈、1,710 MHz 加速時脈,支援 GPU Boost 4.0 技術可因應負載自動超頻至更高時脈,最高 TDP 上升至 320W。
採用 GDDR6X 記憶體顆粒
記憶體方面,「GeForce RTX 3080」改用了全新 GDDR6X 記憶體顆粒,雖然記憶體時脈只有 1,188MHz,傳輸速度卻高達 19Gbps,加上 320 bit 記憶體頻寬介面,令總頻寬提升 760GB/s,對於高解析度、需要啟動大量反鋸齒及特效時會有性能提升。
NVIDIA「GeForce RTX 3080」創始版顯示卡具備了 10 顆 Micron D8BGW (MT61K256M32JE-19) GDDR6X 顆粒,等效時脈為 19 Gbps,合共總高達 10GB 容量,採用16nm 制程、 180-ball FBGA 封裝, VDD/VDDQ 為 1.35V 。
軸向式散熱器設計

GeForce RTX 3080 創始版採用創新軸向式散熱設計,GPU / VRM 及 GDDR6X 記憶體位置被均熱板覆蓋,再用 4 支導熱管傳導致另一組散熱鰭片,搭配兩顆 9cm 風扇,其中一顆反葉設計讓冷空間穿過卡身末端排向 CPU 區域。
全新 12-Pin 供電設計

升級 HDMI 2.1、支援 8K @ 60Hz HDR
為迎接 8K 輸出時代,全新「GA102」繪圖核心更新了顯示輸出引擎,除了支援 DisplayPort 1.4a 接口,同時亦將 HDMI 升級 2.1 版本,無論是 DisplayPort 或是 HDMI 介面均可以提供 8K @ 60Hz 12bit HDR 解析度輸出,這是 4K 像素的 4 倍頻寬需求,更支援 VEGA DSC 1.2 技術提供更高壓縮的無損顯示功能,並且單卡可以提供最高 2 個 8K @ 60Hz 顯示輸出,或是採用 2 組 DisplayPort 接線提供 1 個 8K @120Hz 輸出。
效能測試
GeForce RTX 3080 創始版顯示卡樣本,與 RTX 2080 Super 進行對比測試,以了解新一代「GeForce RTX 3080」的效能水平,另外亦備有 3DMark 及多款遊戲的性能測試。

時脈方面,NVIDIA「GeForce RTX 3080」預設核心時脈為 1,440MHz Base Clock、1,710MHz Boost Clock,支援 GPU Boost 4.0 技術最高可達 2,025MHz。
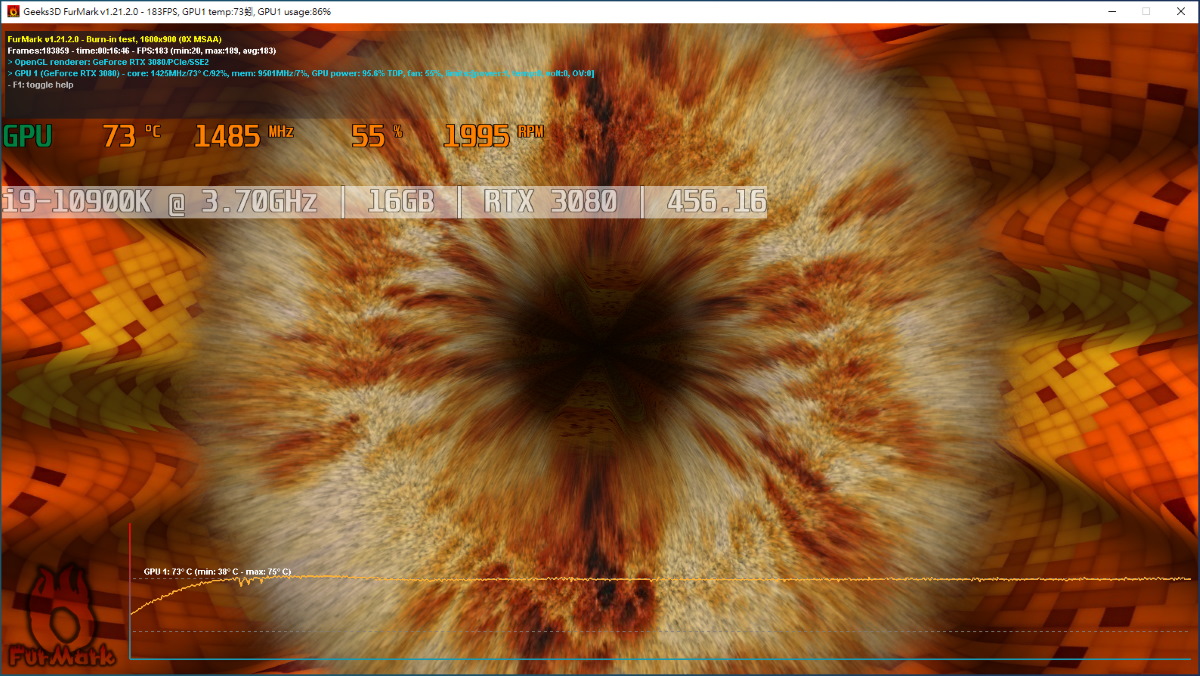
NVIDIA「GeForce RTX 3080 」創始版散熱表現,室溫水平約在 25°C 下進行,閒置時 GPU 溫度維持在 30 °C,經過 30分鐘 GPU 完全負載後,溫度保持在 73°C 水平,GPU 時脈保持在 1,485MHz 的水平。
3DMark 測試
| FireStrike Extreme | FireStrike Ultra | Time Spy | Time Spy Extreme | |
|---|---|---|---|---|
| GeForce RTX 2080 | 13255 | 7153 | 9981 | 5004 |
| GeForce RTX 2080 Super | 13969 | 7594 | 10704 | 5351 |
| GeForce RTX 2080 Ti | 15964 | 8447 | 12263 | 6201 |
| GeForce RTX 3080 | 19277 | 10846 | 16293 | 8217 |
3DMark 作為最廣泛的 3D 性能基準測試,性能對比結果當然不可缺少,根據測試顯示新一代效能級「GeForce RTX 3080」性能大幅超越上代旗艦「GeForce RTX 2080 Ti」。
遊戲測試
冒險聖歌 (Anthem)
| 3840x2160 | AVG FPS |
|---|---|
| GeForce RTX 2080 | 44.4 |
| GeForce RTX 2080 Super | 47.4 |
| GeForce RTX 2080 Ti | 55.4 |
| GeForce RTX 3080 | 86.4 |
Apex 英雄 (Apex Legends)
| 3840x2160 | AVG FPS |
|---|---|
| GeForce RTX 2080 | 66.9 |
| GeForce RTX 2080 Super | 73.4 |
| GeForce RTX 2080 Ti | 80.4 |
| GeForce RTX 3080 | 114.7 |
戰地風雲 5 (Battlefield V)
| 3840x2160 | AVG FPS |
|---|---|
| GeForce RTX 2080 | 69.3 |
| GeForce RTX 2080 Super | 76.2 |
| GeForce RTX 2080 Ti | 88.6 |
| GeForce RTX 3080 | 101.3 |
決勝時刻:黑色行動 4 (Call of Duty: Black Ops 4)
| 3840x2160 | AVG FPS |
|---|---|
| GeForce RTX 2080 | 63.4 |
| GeForce RTX 2080 Super | 66.7 |
| GeForce RTX 2080 Ti | 77.2 |
| GeForce RTX 3080 | 91.3 |
極地戰嚎 5 (Far Cry 5)
| 3840x2160 | AVG FPS |
|---|---|
| GeForce RTX 2080 | 58.6 |
| GeForce RTX 2080 Super | 62.1 |
| GeForce RTX 2080 Ti | 71.4 |
| GeForce RTX 3080 | 86.1 |
戰慄深隧:流亡 (Metro Exodus)
| 3840x2160 | AVG FPS |
|---|---|
| GeForce RTX 2080 | 47.5 |
| GeForce RTX 2080 Super | 51.4 |
| GeForce RTX 2080 Ti | 55.4 |
| GeForce RTX 3080 | 69.7 |
絕地求生 PUBG (Playerunknowns Battlegrounds)
| 3840x2160 | AVG FPS |
|---|---|
| GeForce RTX 2080 | 77.2 |
| GeForce RTX 2080 Super | 82.2 |
| GeForce RTX 2080 Ti | 96.1 |
| GeForce RTX 3080 | 123.6 |
古墓奇兵:暗影 (Shadow of the Tomb Raider)
| 3840x2160 | AVG FPS |
|---|---|
| GeForce RTX 2080 | 47.6 |
| GeForce RTX 2080 Super | 53.1 |
| GeForce RTX 2080 Ti | 63.7 |
| GeForce RTX 3080 | 82.3 |
遊戲效能水平亦是本次測試的重點之一,特別挑選了 8 款不同的遊戲進行測試,其中包括冒險聖歌、Apex 英雄、戰地風雲 5、決勝時刻:黑色行動 4、極地戰嚎 5、戰慄深隧:流亡、 絕地求生 PUBG 及古墓奇兵:暗影等,全部遊戲都會設定成 3840 x 2160 解析度,特效方面亦會調至 Ultra Quality 設定,以測試顯示卡的最大運算能力,可以看到 GeForce RTX 3080 性能高於 RTX 2080 Ti 大約 15~28%。
Bright Memory Infinite , RTX On , DLSS Performance Mode
| AVG FPS | |
|---|---|
| 1080p + RTX On + DLSS Quality | 107 |
| 1080p + RTX On + DLSS Performance | 144 |
| 2K + RTX On + DLSS Quality | 68 |
| 2K + RTX On + DLSS Performance | 100 |
| 4K + RTX On + DLSS Quality | 39 |
| 4K + RTX On + DLSS Performance | 64 |
《Bright Memory: Infinite - 光明記憶:無限》的 RTX 元素有很多,不但包括全域照明、反射、陰影及環境光遮蔽,還加入了焦散效果 (caustics),即是光線經過光滑金屬或透明物體表面反射或折射後,產生匯聚和發散,形成新的光源並照亮周邊的其他物體;以及加入了多層透明效果,亦是暫時對繪圖卡的運算性能需求最高的遊戲之一。支援全新的 DLSS Ultra Performance Mode,並提供「Quality」、「Balanced」、「Performance」及「Ultra Performance (只限 8K)」四個級別選擇。
測試結果顯示,在 4K 解析度、RTX 質素設定為「高」的設定下,開啟 DLSS「Performance Mode」後平均 FPS 達到 64,而且最低 FPS 為維持在 40,對比「Quality Mode」的 16 提升達 2 倍以上,最起碼會是「可以玩」的狀態,而不再是只能作展示的存在。
Boundary RTX On , DLSS Performance Mode
| AVG FPS | |
|---|---|
| 1080p + RTX On + DLSS Quality | 104.7 |
| 1080p + RTX On + DLSS Performance | 145.6 |
| 2K + RTX On + DLSS Quality | 70.2 |
| 2K + RTX On + DLSS Performance | 100 |
| 4K + RTX On + DLSS Performance | 35 |
| 4K + RTX On + DLSS Performance | 50.6 |
《Boundary 邊境》遊戲加入了相當多的光線追蹤技術元素,包括全域照明、反射、陰影及環境光遮蔽,而為了提升遊戲在開啟所有 RTX 元素下的性能表現,遊戲支援全新的 DLSS Ultra Performance Mode,它是專為 8K RTX 遊戲打造且經過全新訓練的 AI 超高解析度模型,只需要渲染九分之一的像素量即能提供與原生分辨率相媲美的畫質。而且與上代的 DLSS 技術只能選擇開啟或關閉的選項不同,它能夠提供「Quality」、「Balanced」、「Performance」及「Ultra Performance」四個級別選擇,讓玩家在畫質及性能中選擇平衡點,但需要注意的是 Ultra Performance Mode 僅支援 8K 解析度下開啟。
測試結果顯示,在同樣的解析度設定下,DLSS「Quality Mode」及「Performance Mode」得出的平均 FPS 相差 37 至 25,差不多有著 60% 以上的效能差異,可見 DLSS 技術絕對是 RTX 遊戲中不可或缺的一部分。
編輯評語
NVIDIA GeForce RTX 3080 將效能級 GPU 提升至另一個高度,讓 3A 遊戲大作也可以用 4K 解析度 + RTX On 運行,而且售價比 GeForce RTX 2080 Ti 更便宜, RTX 20 系列的 RTX On 只是展示性,RTX 30 才是真正玩到 RTX On 的世代。
以上內容及測試數據為 HKEPC 獨家授權給 UNIKO's Hardware 編譯

