

AMD 在今年 7 月時推出了採用 TSMC 7nm 全新製程製造的第三代 Ryzen 3000 系列處理器,擁有旗艦高達 12 核心的 Ryzen 9 3900X,及高階 8 核心Ryzen 7 3800X 和 3700X,主流 6 核心Ryzen 5 3600X 與 3600,還有即將上市的 AM4 最高旗艦 16 核心 Ryzen 9 3950X,當然也有入門型號的 APU 系列 Ryzen 5 3400G、Ryzen 3 3200G,從高到低全部皆在今年 7 月時通通上市,至此也相隔了近 4 個月的時間,AMD 也不負眾望的為市場帶來了一片好評。
AMD Zen2 全新的微架構
受惠於微架構的改良,IPC 性能相較上代「Zen+」平均提升了約 15%,加上全新 7nm 制程改進,令核心時脈再提升 350MHz,整體性能提升達 21%。
這次全新的 7nm 制程,讓 AMD 可以在現有的 Socket AM4 封裝放進更多的核心,以高性價比及更多核心的優勢作賣點,相同 CPU 核心數規格售價較 Intel 便宜,相同價位下 CPU 核心更多、性能更高。
AMD 這三年來的進步,無論是在制程或微架構都按照時程表發展並準時實現,在 Socket AM4 平台實現 3 個微架構及制程改良、CPU 核心數目提升 4x、PCIe 頻寬提升 1x,記憶體頻寬提升了 33%,相較 Intel 仍保持老舊的 14nm 制程,兩家平台相比之下進步程度有著很大的差距。
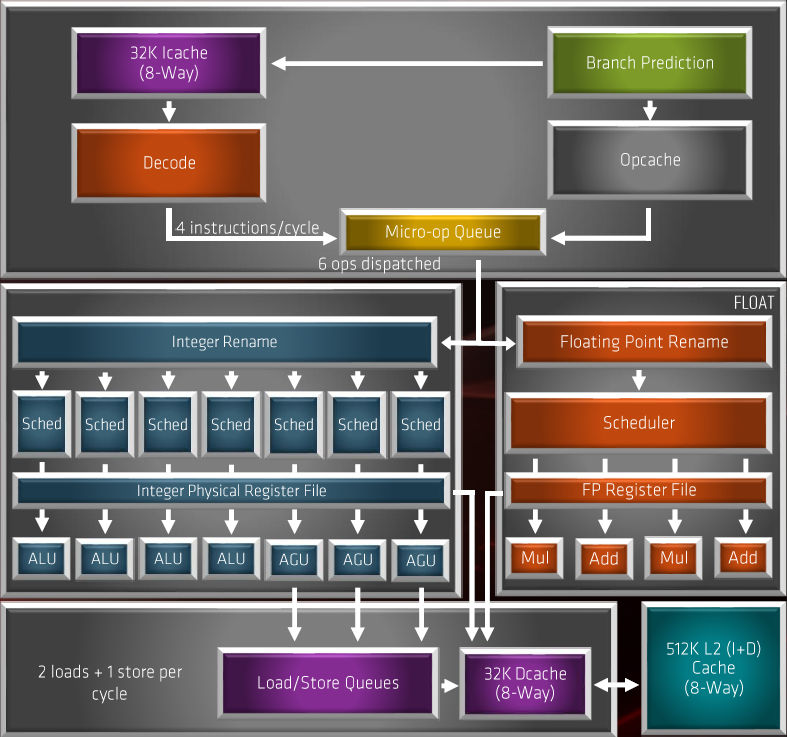
▲Zen 2 微架構 Block Diagram。
Zen2 微架構有很明顯的改良,包括增加內部頻寬、提升運算單元使用率、提升緩存命中率、提升單一週期指令執行數等等,主要改進及全新設計包括︰
- 改用 256bit Single-Op 浮點單元。
- μOps Cache 容量倍增至 4096 byte。
- 全新的 TAGE 預測分支設計。
- 增至 3 組 AGU 單元 。
- 增加 Load/Store Bandwidth。
- L3 Cache 容量提升 1 倍。
- 改良 Fetch 及 Pre-Fetch 能力。
- 改良 ALU 及 AGU Schedulers。
- 增加 Register File 容量。
- IMC 控制器改良、提升至DDR4-3200+。
改進的 FETCH
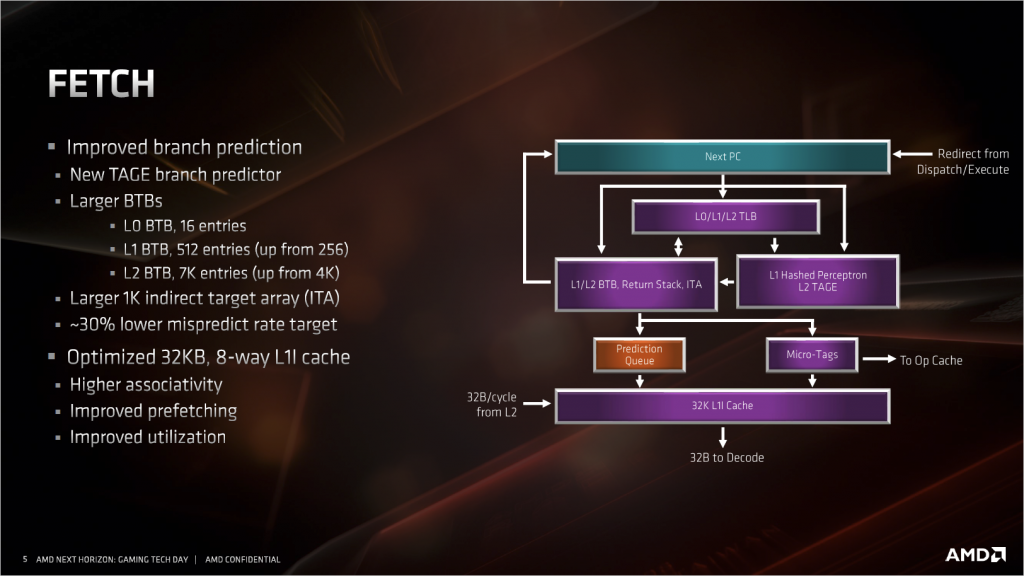
▲改進版的分支預測單元、一級指令緩存 。
這部分最大的改進是把原來的兩級神經網路分支預測器的第二級,換成了新的TAGE分支預測器。傳統的分支預測器是單層的感知器。新的 TAGE 分支預測器全名叫 TAgged GEometric length predictor,是目前最先進的分支預測器。
除了分支預測的改進之外,L1I 的也有不少變化,雖然容量從 64KiB 減少到 32KiB,但組相關從4路增加到8路,L1I 的頻寬是 AMD 的傳統強項,32Byte/cycle 對 Intel 的 16Byte/ cycle。
解碼 Decode

▲容量擴充的 Ops cache 和改進版指令融合。
AMD 把微指令緩存(Ops cache)的容量翻倍了,這樣可以緩存更大的代碼塊,對於復雜的函數和循環來說很有幫助。Ops cache 是用來緩存解碼器解碼出來的宏指令(Macro op),第一可以為後面的亂序核心提供更高的宏指令頻寬,第二可以減少解碼器(Decoder)的工作,避免在解碼器上消耗過多的電力,最後還順帶減少了等效的流水線級數,避免過高的分支預測失敗。
Intel 的處理器也有一個對應的 μop cache,功能也相同,不過僅僅只有 6 μops/c 的頻寬,低於AMD 的 8 Macro ops/c,容量上也只有 1536個μops,遠遠低於 Zen2 的 4096。實際 μop 的比Macro op 更簡單,X86 指令解碼出來的 μops 也比 Macro ops 多,Intel 的 μop cache 容量就顯得更小了。
FPU 浮點運算單元

▲改進的FPU雙倍寬度。
之前 AMD 在 Zen1 的產品上常被人詬病的就是這點。Zen1 的 FPU 由 4 個 128bit 的 SIMD 單元構成,一般浮點運算可以支援 4*128bit 的 AVX/SSE 或者 2*256bit 的 AVX 並行,這一點上和 Intel 相比其實沒有任何劣勢,甚至在 128bit 指令的執行上還有高出一倍的優勢。但是在FMA 指令上,只有 2*128bit 或者 1*256bit,因為 FMA 是由加法和乘法 SIMD 拼接完成的,並不像 Intel 的 2*256bit 是獨立的單元,結果就是在各種測試浮點單元理論吞吐率的軟體中被 Intel 領先不少。
另外一點,這裡 FPU 雖然名義上浮點單元,但整數 SIMD 指令也是在這裡完成的。針對整數的 AVX2 指令,AMD 當時可能考慮應用沒到那麼廣泛,所以沒有設計太多的執行單元。到了這次 Zen2 架構中,AMD 把所有 SIMD 單元的寬度都直接加倍了,現在有 4*256bit SIMD,兩個浮點加法 SIMD 和兩個浮點乘法 SIMD。
上面提到對 Intel 擁有高出一倍效率的128bit 指令優勢保持不變以外,在 256bit 的 AVX 指令上,現在也同樣擁有了高出一倍的優勢,FMA 指令雖然也是拼接完成,但得益於暴力的 SIMD 寬度翻倍,性能和 Intel 的也能持平了,形成了在最差 AMD 也不會輸,一般情況還能超越你多出一倍的優勢局面。
AVX2 方面 Zen2 同樣也基本做了翻倍處理,基本上除了飽和算術指令外,其他的都能達到或超越 Intel 的水平,可以說是互有勝負。
整數單元 IEU
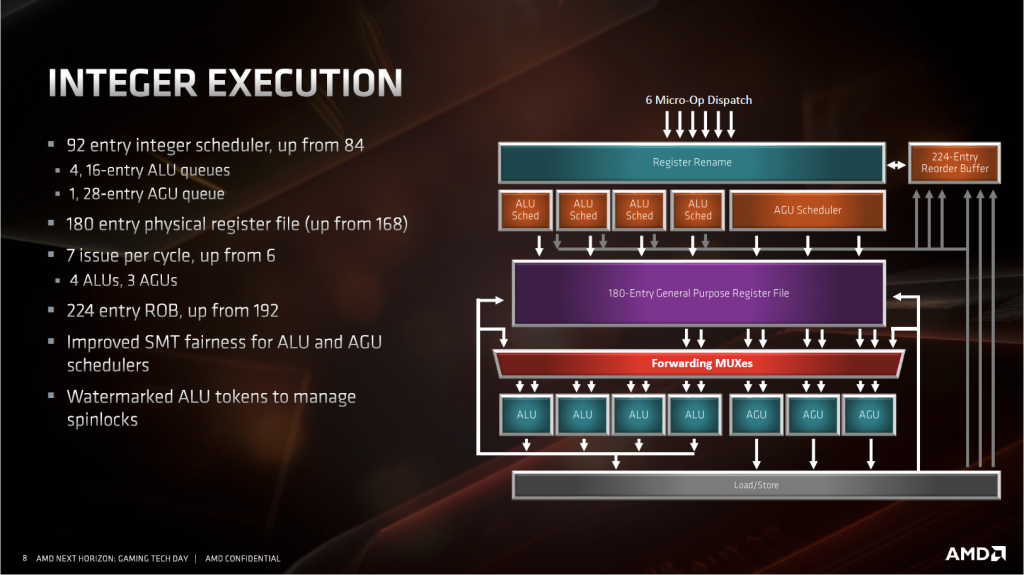
▲Zen2 微架構的INT整數運算群。
整數單元的性能主要看指令級並行能開發到什麼程度。Zen2 將每一個部件都進行了擴充,期望能獲得更高的 IPC。這些部件的提升幅度和 Intel 的從 Haswell 到 Skylake 幾乎完全一致。
除了這幾樣,AMD 在訪存方面也做了加強。增加了一個 AGU 和它對應的發射端。Zen1 只有兩個 AGU,所以 Zen1 最多只能做到兩讀或者一讀一寫,這對 IPC 來說很不利。大部分指令通常需要兩個數據來源,然後產生一個結果。兩個 AGU 在前一條指令寫結果的時候,只能讀取一條數據來源,然後額外消耗一個週期來讀取另一個來源,再下一個週期 ALU 才能開始執行運算,中間就多了一個空閒的周期。而三個 AGU 就不同了,前一條指令回寫結果的同時,可以同時讀取下一條指令所需的兩個數據,再下一個週期 ALU 就可以直接進行運算了,減少了一個週期,所以 AMD 改到 3 AGU 非常的合理。
訪存單元(LSU)和緩存架構
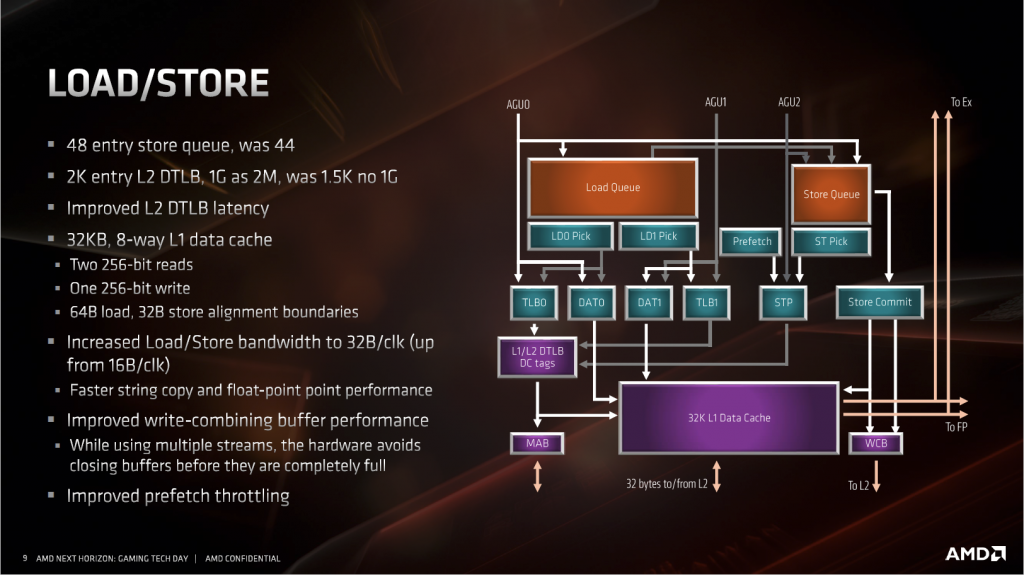
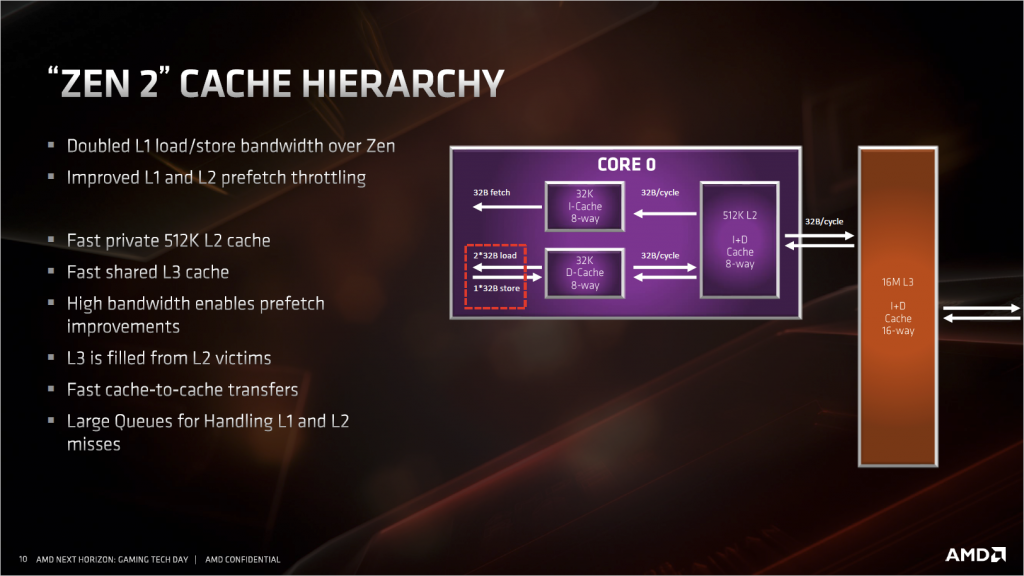
訪存單元這次的改進主要是為了配合 AGU 和浮點單元的改進。LSU 方面因為 AGU 增加到三個,所以 LSU 這裡也要配合著變成每週期能接受 2 讀 1 寫的設定。浮點單元部分,SIMD 的寬度加倍到了 256bit,所以同樣這裡也要從原來的 128bit 讀寫變成 256bit 讀寫,對應到 L1 緩存上就是頻寬加倍。
其他改進的地方還有存儲隊列長度增加到 48。L2 數據 TLB 增加到 2K entry,更重要的是增加了 1G 大頁面的支援,這對於 Windows 操作系統來說意義不大,但是對於 Linux 操作系統來說,很多高性能資料庫、軟體、驅動,例如 DPDK,Oracle 等等,都依賴於 1G 的大頁面來減少 TLB miss,幫助不小。
Zen2 新指令

▲Zen2 微架構新增了 3 條指令。
Zen2 新增了 3 條 Cache 指令 CLWB、QoS 及 WBNOINVD,CLWB 和 QoS 均為通用指令並已加進 Windows 10 May 2019 (1903)。
CLWB 指令可以讓系統在任何 Cores 或 Cache 進行 Write Back,這個是針對未來的非揮發性記憶體而設計的,目的是清空所有緩存,避免關電的時候還有數據沒有寫回快閃記憶體中。
QoS 指令則可以針對 Cache 及 Memory 進行管理以提高最大吞吐量,在 High Concurrency 的環境中,給與需要的線程足夠的資源來提高整體的吞吐率,並對於 VM 虛擬化有很大作用。
WBNOINVD 將緩存的數據寫回記憶體,但不更改它為失效狀態,失效狀態意味著這段數據馬上需要被替換掉,通常寫回記憶體就意味著這段緩存不會再頻繁使用了。下面舉的例子可以說明他的作用,因為 Direct Memory Access 只能訪問記憶體,使用這個指令將緩存數據寫回記憶體之後,CPU 可以繼續使用這段緩存中的數據,而 Direct Memory Access 也可以正常的從記憶體中讀取數據傳輸到別的設備。另外也可針對 AM D新一代的 GPU 使用,讓 Cache 中已修改的資料可以快速回寫到記憶體,能有效降低 CPU to GPU 的回寫延遲。
CPU Chiplet 多晶片結構

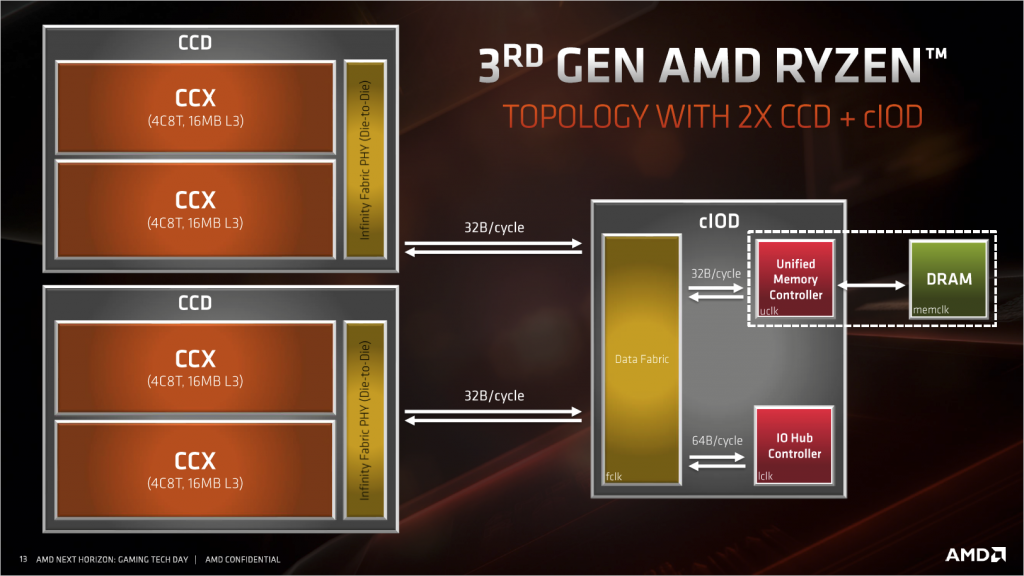
▲Zen2 8 核心及以下都是一個 CPU die 和一個 IO die,往上則是兩個 CPU die 和一個 IO die。
所有記憶體和 PCIe 鏈接都是由 IO die 提供的,IO die 沒有區別,那麼記憶體通道和 PCIe 數量就沒有區別。頻寬上 CCD 與 cIOD 之間的頻寬為 32Byte/c,工作頻率為 FCLK 頻率,一般情況等於記憶體的實際工作頻率(不是DDR頻率),但實際可以自己以 33Mhz 為步進手動調整,在 3200MHz 的記憶體頻率頻寬為 51.2GByte/s。
而 cIOD 內部,DF 與記憶體控制器之間,頻寬也是 32Byte/c,工作頻率為 UCLK 頻率,這部分頻率和記憶體直接掛鉤,可以設定為 1:1 記憶體工作頻率,也可以設為 1:2 記憶體工作頻率,這種設定減小了記憶體跑高頻時給記憶體控制器帶來的壓力,以 3200MHz 的記憶體使用 1:1 的話,頻寬剛好是 51.2GByte/c,和雙通道記憶體頻寬一致,但如果使用 1:2 的設定則只有實際記憶體的一半,基本上 1:2 模式除了可以把記憶體頻率超高之外,實際上沒有幫助。
起初對於這種 Chiplet 多晶片膠水設計,包括我及很多人都認為,多了一個 IO die 記憶體延遲會變很差,甚至上市前傳出 Ryzen 三代的記憶體延遲絕對不低於 80ns。
後來測試 R9 3900X 的 AIDA64 記憶體延遲,甚至比一代的還低 3ns,並且考慮到兩個平台可以跑的記憶體頻率,實際上三代 Ryzen 在這點上是遠遠領先於一代的。三代平台配上現在 CP值很高的海力士 CJR / JJR / DJR 或美光 e-die 等等,幾乎都可以很輕鬆的超頻至 3800Mhz(搭配 FCLK 1900 依 IO Die 體質不同,FCLK 上限頻率也不同)並穩定使用。
除了記憶體延遲之外還有一個問題,那就是兩個 CPU die 的 Ryzen 會不會因 CCD 之間的互聯造成延遲比上一代 Threadripper 還高,畢竟 Threadripper 是兩個 CPU die 直接互聯,而三代 Ryzen 還要多經過一個 IO die。對此做了記憶體的延遲測試,使用每個核心內的第一個 SMT 核心進行測試。
Zen1 平台,CCX 內的核心之間互聯延遲約在 41~49ns 之間,而不同 CCX 中的核心之間延遲則約 127~129ns 之間。
Zen2 平台,CCX 內的核心之間互聯延遲基本穩定在 31ns,另外 R9 3900X 的頻率更高,所以延遲也會更低。而不同 CCX 核心之間的延遲則比 Zen1 大幅下降了近 40%,範圍約在76~80ns,可以確定 CCX 之間的 Data Fabric 有了重大改進。
而 CCD 之間的互聯延遲,竟然也只有 78~80ns,和 CCX 之間的互聯延遲幾乎相當,非常的難以置信,完全想不到這是怎麼做到的,難道因為 CPU die 之間還有直接的互聯? 為了驗證這個想法,於是再測 1900X 的記憶體延遲。
1900X 每個核心只有開啟一個C CX,所以就沒有 CCX 之間的延遲。另外因頻率較高的關係,所以 CCX 內的延遲看起來也不錯,約在 25~42ns,但不是很穩定。測試不同組 CCX 之間的延遲竟高達到 230ns 以上,比 1700X 的 CCX 之間延遲幾乎高了一倍,所以得出結論,即便是 die 直連也會有巨大的延遲影響,那麼 3900X 的 CCD 互聯延遲就真的非常厲害了,完全跑在 6Xns,不用擔心多個 CCD 會不會有很高的延遲問題。
總結
AMD 這次 Zen2 微架構的變化,不論是 IPC 的提升、核心數、快取、Pcie 4.0 標準...等等等等,都是全面的改進,並且 CCD 的低延遲設計也對之後上市的 Threadripper 系列帶來非常大的幫助,不像上代需要特別對 NUMA 的優化。
這代在遊戲性能上提升非常明顯,幾乎已經和 Intel 處理器平台的表現一致了,同時在生產力方面,例如影音轉檔、渲染、準專業的運算研究等等,表現那更是虎虎生風。
現在 AMD 已經轉由台積電代工,依照目前的進度及計畫都是在順利的狀況,自從 AMD Zen上市後就為市場帶來了革命性的變化,期待之後 AMD 能再推出讓人驚呼的新產品。
老羊

