

AMD 正式啟動 ROCm 7 計算軟體堆疊,主打支援 MI350 系列 GPU,並在 AI 推理與訓練效能上大幅提升。官方資料顯示 ROCm 7 的 FP8 吞吐量表現優異,比 NVIDIA Blackwell B200 高出 30%,成為挑戰 CUDA 生態的重要一步。
AMD 的 AI 攻城車 ROCm 7
長期以來,NVIDIA CUDA 軟體堆疊幾乎壟斷了 AI 開發領域,AMD 難以切入市場。如今,根據外媒 Phoronix 的報導,AMD 正式啟動 ROCm 7 軟體堆疊的發布準備,目標是打造能與 CUDA 抗衡的替代方案。
在 Advancing AI 大會上,AMD 首度揭露 ROCm 7 的技術細節,並強調其針對 AI 推理工作負載的最佳化。相比前代 ROCm 6,性能提升高達 3.5 倍,不僅在推理速度上大幅進步,訓練效能也得到強化。
AMD 在展示中指出,Instinct MI355X GPU 在 DeepSeek R1 測試中展現出驚人的表現,FP8 吞吐效能比 NVIDIA Blackwell B200 高出 30%。ROCm 7 不僅僅是軟體最佳化,更是 AMD 與自家硬體深度整合後的突破。
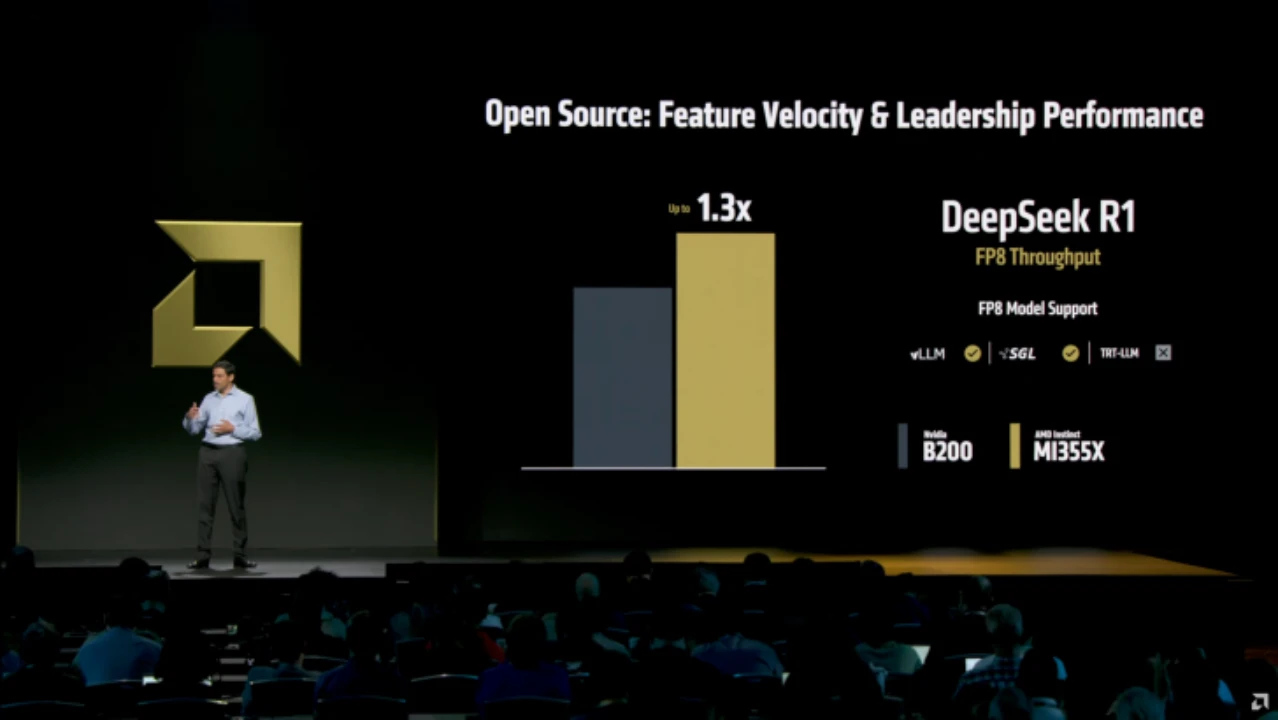
ROCm 7 的重點不僅在效能提升,還涵蓋新演算法與模型支援、更強大的集群管理、企業級功能,以及完整的 MI350 系列 GPU 支援。根據 GitHub 代碼標籤顯示,rocm-7.0.0 已出現在 HIP、AOMP 與 ROCm Libraries,可以預期正式發布即將到來。
雖然 AMD 尚未公布 ROCm 7 的確切上線日期,但一旦推出,將成為其 AI 生態的重要戰略工具。若 ROCm 7 能持續擴大軟體支援與開發者採用率,勢必成為 NVIDIA CUDA 的真正競爭者。
延伸閱讀











